Java编程思想集合篇(二)
Java HashMap为什么通过(n - 1) & hash 获取哈希桶数组下标?
看过HashMap源码人应该都知道HashMap是如何根据hash值来计算哈希桶数组下标的,就是通过(n - 1) & hash来计算的,那么为什么用的是位运算而不是取模运算(hash % n)呢?
获取hash桶数组下标源码
if ((p = tab[i = (n - 1) & hash]) == null){
tab[i] = newNode(hash, key, value, null);
}
一. 位运算与取模运算时间比较
package com.polymorphic;
public class Test {
int a = 1;
int number = 100000; // 数据集数量,初始定义为十万
// 位运算
public long bitwise() {
long start = System.currentTimeMillis();
//从十万开始,一直到Integer的最大值,计算所需时间
for (int i = number; i > 0; i++) {
a &= i;
}
long end = System.currentTimeMillis();
long time = end - start;
System.out.println("位运算时间为:" + time + "ms");
return time;
}
// 取模运算
public long module() {
long start = System.currentTimeMillis();
for (int i = number; i > 0; i++) {
a %= i;
}
long end = System.currentTimeMillis();
long time = end - start;
System.out.println("取模运算时间为:" + time + "ms");
return time;
}
public static void main(String[] args) {
Test t = new Test();
t.bitwise();
t.module();
}
}
运行结果为
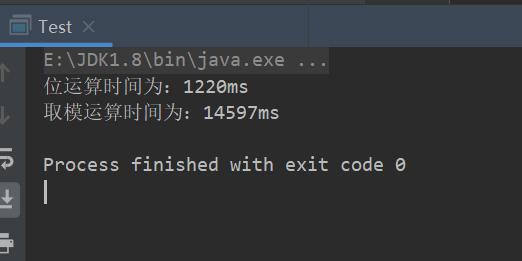
从测试结果我们可以看出,如果数据集足够的大,那么取模运算的时间将会是位运算时间的十几倍。这只是一方面,如果数据集足够大的话,HashMap的初始容量肯定不够,这也触发了HashMap的扩容机制。所以采用二进制位操作 &,相对于%能够提高运算效率
二.位运算是如何保证索引不越界
讲到这,我们也就要想想为什么HashMap的容量是2的n次幂?两者之间有着千丝万缕的联系。
当 n 是2的次幂时, n - 1 通过 二进制表示即尾端一直都是以连续1的形式表示的。当(n - 1) 与 hash 做与运算时,会保留hash中 后 x 位的 1,这样就保证了索引值 不会超出数组长度。
同时当n为2次幂时,会满足一个公式:(n - 1) & hash = hash % n。