Java集合类(一)
-
集合的概念
-
Collection接口和常用方法
-
List接口和常用方法
-
ArrayList底层源码即注意事项
-
Vector底层结构和源码解析
-
LinkedList底层结构和源码解析
集合的概念
-
由于前面保存多个数据使用的是数组,而数组保存数据会有一些不足的地方。
- 长度开始时必须指定,而且一旦指定,不能更改
- 保存的必须为同一类型的元素
- 使用数组进行增加元素/删除会比较麻烦
-
若使用集合来处理数据的话,这类问题将会减少。集合的好处如下:
- 可以动态保存任意多个对象,使用比较方便!
- 提供了一系列方便操作对象的方法:add、remove、set、get等
- 使用集合添加、删除新元素的代码更加简洁了
-
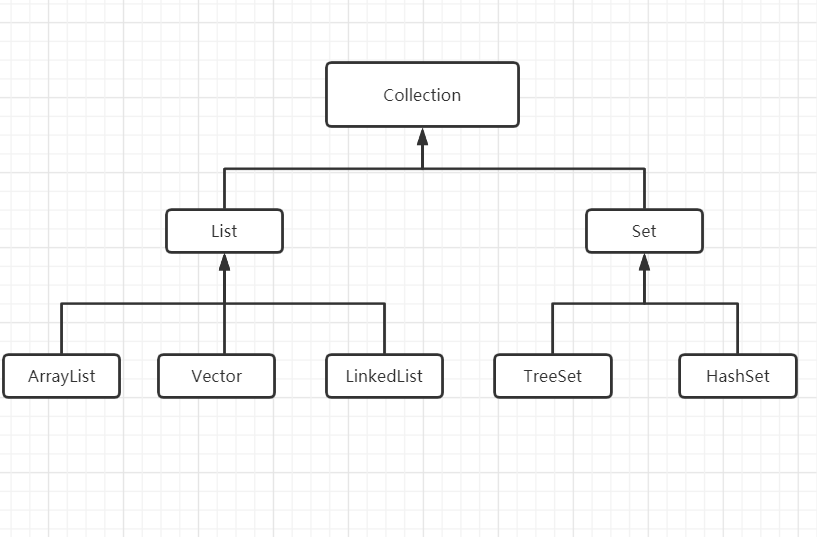
集合的框架体系
Collection接口实现子类:
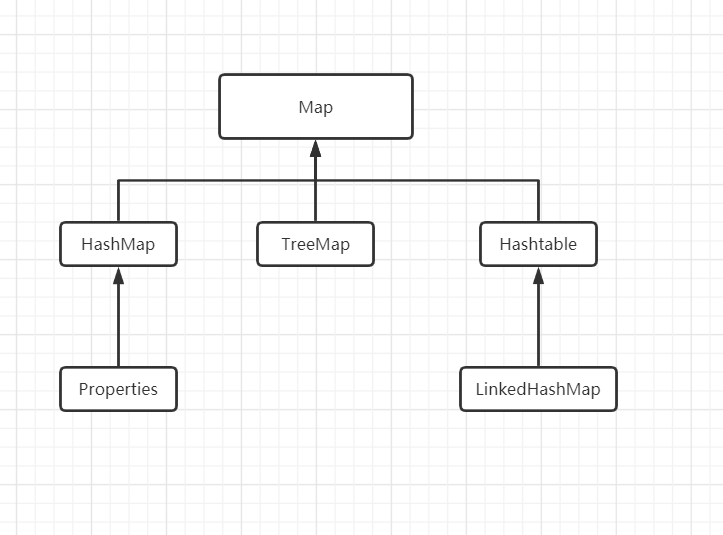
Map接口实现子类:
-
集合主要有两种(单列集合,双列集合)
-
Collection接口有两个重要的子接口List、Set,他们的实现子类都是单列集合
ArrayList arrayList = new ArrayList(); arrayList.add("jack"); arrayList.add("tom"); -
Map接口的实现子类是双列集合,即以K-V形式存放数据的
HashMap hashMap = new HashMap(); hashMap.put("No1","jack"); hashMap.put("No2","tom");
-
Collection接口和常用方法
-
Collection接口的特征
-
Collection实现子类可以存放多个元素,每个元素可以是Object
-
有些Collection的实现类,可以存放重复的元素,有些不可以
-
Collection实现类有些是有序的(List),有些不是有序的(Set)
-
Collection接口没有直接的实现子类,是通过它的子接口Set和List来实现的
-
-
Collection接口的常用方法
- add:添加单个元素
- remove:删除指定元素
- contains:查找元素是否存在
- size:获取元素个数
- isEmpty:判断是否为空
- clear:清空
- addAll:增加多个元素
- containsAll:查找多个元素是否都存在
- removeAll:删除多个元素
以Collection的实现子类演示上述方法
package com.conllection_; import java.util.ArrayList; import java.util.Collection; import java.util.List; public class Collecyion_ { @SuppressWarnings({"all"}) public static void main(String[] args) { List List = new ArrayList(); //add:添加单个元素 List.add(10); List.add("java"); List.add(true); System.out.println("List="+List); //remove:删除指定元素 List.remove(true); System.out.println("List="+List); //contains:查找元素是否存在 System.out.println(List.contains(10)); //size:获取元素个数 System.out.println(List.size()); //isEmpty:判断是否为空 System.out.println(List.isEmpty()); //clear:清空 List.clear(); System.out.println("List="+List); //addAll:增加多个元素 List List2 = new ArrayList(); List2.add("红楼梦"); List2.add("三国演义"); List2.add("水浒传"); List.addAll(List2); System.out.println("List="+List); //containsAll:查找多个元素是否都存在 System.out.println(List.containsAll(List2)); //removeAll:删除多个元素 List.removeAll(List2); System.out.println("List="+List); } }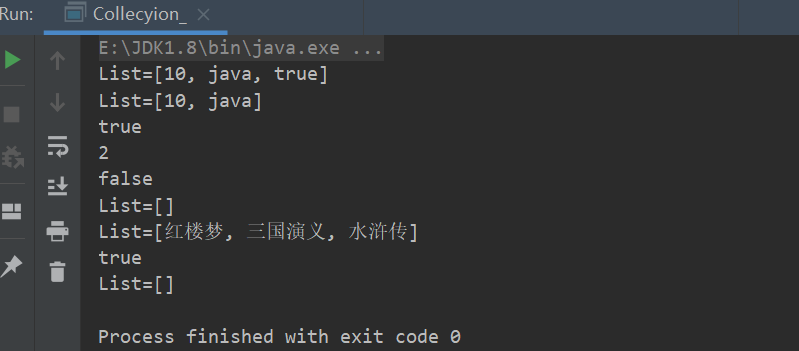
-
Collection接口使用Iterator(迭代器)遍历元素
- Iterator对象称为迭代器,主要用于遍历Collection集合中的元素
- 所有实现了Collection接口的集合类都有一个iterator()方法,用以返回一个实现了Iterator接口的对象,即可以返回一个迭代器
- Iterator仅用于遍历集合,Iterator本身并不存放对象
- hasNext():判断是否还有下一个元素
- next():将下移以后集合位置上的元素返回
代码演示:
Collection_Book类
package com.conllection_; public class Collection_Book { private String name; private String author; private double price; public Collection_Book(String name, String author, double price) { this.name = name; this.author = author; this.price = price; } @Override public String toString() { return "Collection_Book{" + "name='" + name + '\'' + ", author='" + author + '\'' + ", price=" + price + '}'; } }Collection_Iterator类
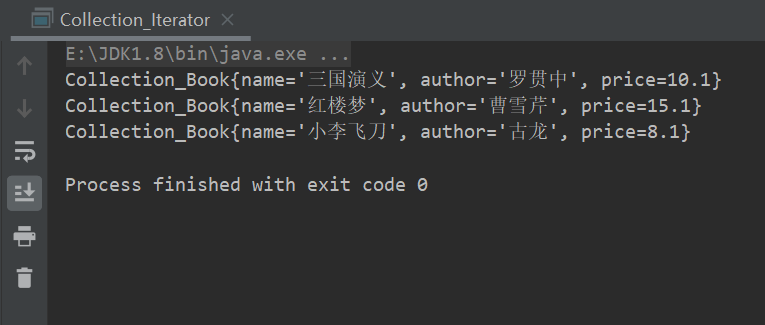
package com.conllection_; import java.util.ArrayList; import java.util.Collection; import java.util.Iterator; import com.conllection_.Collection_Book; public class Collection_Iterator { public static void main(String[] args) { Collection col =new ArrayList(); col.add(new Collection_Book("三国演义","罗贯中",10.1)); col.add(new Collection_Book("红楼梦","曹雪芹",15.1)); col.add(new Collection_Book("小李飞刀","古龙",8.1)); //创建col对应的迭代器 Iterator iterator = col.iterator(); //使用while遍历循环 while (iterator.hasNext()){ //因为迭代器取到的数据可以是任意类型的,所以用Object Object obj= iterator.next(); System.out.println(obj); } } }运行结果
hasNext()的返回值为Boolean,
next()的返回值可以为任意类型
注意:当退出while循环后,这是iterator迭代器指向最后一个元素,此时再使用iterator.next()系统会报错。
如果要再次遍历,我们需要重置迭代器:
iterator = col.iterator();//重置迭代器 -
在IDEA中可以使用itit快捷生成
while (iterator.hasNext()){ Object obj= iterator.next(); System.out.println(obj); } -
ctrl+j可以看到所有快捷键
-
Collection接口使用增强for循环来遍历元素
- 增强for就是简化版的iterator,本质一样,只能用于遍历集合或素组
基本语法
for(Object object : col){ System.out.println(object); }代码演示
Collection_For类
package com.conllection_; import java.util.ArrayList; import java.util.Collection; public class Collection_For { public static void main(String[] args) { Collection col =new ArrayList(); col.add(new Collection_Book("三国演义","罗贯中",10.1)); col.add(new Collection_Book("红楼梦","曹雪芹",15.1)); col.add(new Collection_Book("小李飞刀","古龙",8.1)); for(Object object : col){ System.out.println(object); } } }运行结果与使用迭代器的一致。
我们在**for(Object object : col)**这行代码加一个断点,通过Debug,可以发现增强for会依次调用迭代器的底层方法!
public Iterator<E> iterator() { return new Itr(); }public boolean hasNext() { return cursor != size; }public E next() { checkForComodification(); int i = cursor; if (i >= size) throw new NoSuchElementException(); Object[] elementData = ArrayList.this.elementData; if (i >= elementData.length) throw new ConcurrentModificationException(); cursor = i + 1; return (E) elementData[lastRet = i]; }所以,我们可以得知,增强for的底层仍然是迭代器!
List接口和常用方法
List接口是Collection接口的子接口
-
List集合类中元素有序(即添加顺序与取出顺序一致)、且可重复
-
List集合中的每个元素都有其对应的顺序索引,即支持索引
-
List容器中的元素都对应一个整数型的序号记载其在容器中的位置,可以根据序号存取容器中的元素
-
List接口常用的实现类有:ArrayList、LinkedList、Vector
package com.conllection_.lists; import java.util.ArrayList; import java.util.List; public class List_ { public static void main(String[] args) { List list = new ArrayList(); //1. List集合类中元素有序(即添加顺序与取出顺序一致)、且可重复 list.add("tom"); list.add("mary"); list.add("heng"); list.add("tom"); list.add("jack"); list.add("tom"); System.out.println("list="+list); //2. List集合中的每个元素都有其对应的顺序索引,即支持索引 // 索引从0开始 System.out.println(list.get(3)); } }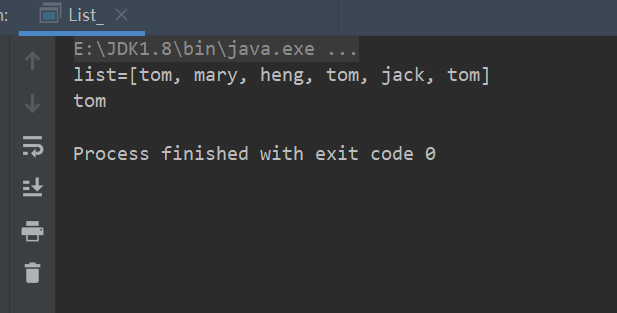
List接口的常用方法
-
void add(int index,Object ele):在index位置插入ele元素。
-
bollean addAll(int index,Collection eles):在index位置开始讲eles中的所有元素添加进来。
-
Object get(int index):获取指定index位置的元素。
-
int indexOf(Object obj):返回obj在集合中首次出现的位置。
-
int lastIndexOf(Object obj):返回obj在当前集合中末次出现的位置。
-
Object remove(int index):移除指定index位置的元素,并返回此元素。
-
Object set(int index,Object ele):设置指定index位置的元素为ele,相当于是替换。
-
List subList(int formIndex,int toIndex):返回从formIndex到tolIndex位置的子集合。
代码演示:
package com.conllection_.lists; import java.util.ArrayList; import java.util.List; public class ListMethod { public static void main(String[] args) { List list1 = new ArrayList<>(); list1.add("tom"); list1.add("cat"); list1.add("jack"); list1.add("mary"); list1.add("tom"); System.out.println("list1 = "+list1); // 1. void add(int index,Object ele):在index位置插入ele元素。 list1.add(2,"nancy"); System.out.println("list1 = "+list1); // 2. bollean addAll(int index,Collection eles):在index位置开始讲eles中的所有元素添加进来。 List list2 = new ArrayList(); list2.add("heng"); list2.add("minster"); System.out.println("list2 = "+list2); list1.addAll(3,list2); System.out.println("list1 = "+list1); // 3. Object get(int index):获取指定index位置的元素。 System.out.println(list1.get(3)); // 4. int indexOf(Object obj):返回obj在集合中首次出现的位置。 System.out.println(list1.indexOf("tom")); // 5. int lastIndexOf(Object obj):返回obj在当前集合中末次出现的位置。 System.out.println(list1.lastIndexOf("tom")); // 6. Object remove(int index):移除指定index位置的元素,并返回此元素。 System.out.println(list1.remove(0)); System.out.println("list1 = "+list1); // 7. Object set(int index,Object ele):设置指定index位置的元素为ele,相当于是替换。 //index必须是存在的下标,越界会报错! //返回被替换的值 System.out.println(list1.set(3,"rui")); System.out.println("list1 = "+ list1); // 8. List subList(int formIndex,int toIndex):返回从formIndex到tolIndex位置的子集合。 //返回的子集合为前闭后开区间! forIndex <= subList < toIndexE System.out.println(list1.subList(2,4)); } }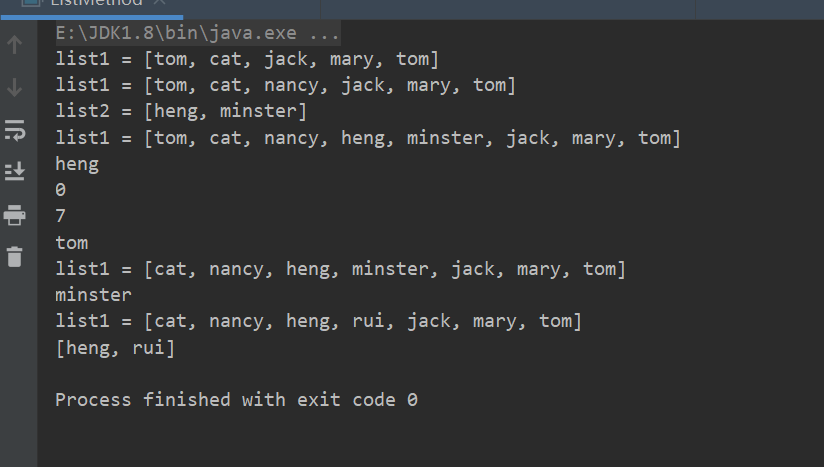
-
List的三种遍历方式
package com.conllection_.lists; import java.util.ArrayList; import java.util.Iterator; import java.util.List; public class ListFor { public static void main(String[] args) { List list = new ArrayList(); list.add("jack"); list.add("tom"); list.add("成志恒"); list.add(1); System.out.println("====迭代器遍历===="); // 1.迭代器遍历 Iterator iterator = list.iterator(); while (iterator.hasNext()) { Object obj = iterator.next(); System.out.println("obj = "+obj); } System.out.println("====增强for遍历===="); // 2.增强For for (Object o : list){ System.out.println("obj = "+o); } System.out.println("====普通For遍历===="); // 3.普通For for (int i =0; i< list.size();i++){ System.out.println("obj = "+list.get(i)); } } }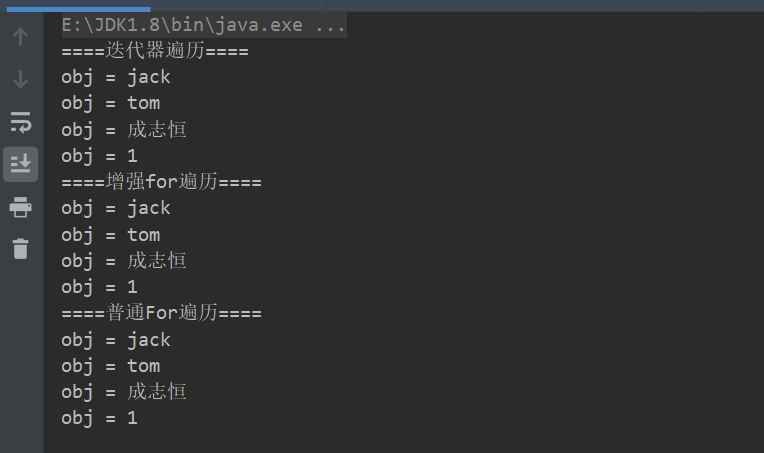
List的其他实现子类(LinkedList、Vector)也可以使用上述三种方式进行遍历
-
练习:

Book类:
package com.conllection_.lists; public class Book { private String name; private double price; private String author; public Book(String name, String author,double price) { this.name = name; this.author = author; this.price = price; } public String getName() { return name; } public void setName(String name) { this.name = name; } public double getPrice() { return price; } public void setPrice(double price) { this.price = price; } public String getAuthor() { return author; } public void setAuthor(String author) { this.author = author; } @Override public String toString() { return "名称:"+name+"\t\t价格:"+price+"\t\t作者:"+author; } }ListExercise02类:
package com.conllection_.lists; import java.util.*; public class ListExercise02 { public static void main(String[] args) { List list = new Vector(); list.add(new Book("红楼梦","曹雪芹",100)); list.add(new Book("三国","罗贯中",80)); list.add(new Book("西游记","吴承恩",90)); list.add(new Book("水浒传","施耐庵",9)); //list.add(new Book("西游记","吴承恩",90)); for (Object o : list){ System.out.println(o.toString()); } sort(list); System.out.println("==排序后=="); for (Object o : list){ System.out.println(o.toString()); } } public static void sort(List list){ int listSize = list.size(); for (int i = 0; i <listSize-1 ; i++) { for (int j = 0; j < listSize-1-i; j++) { //取出对象Book Book book1 = (Book) list.get(j); Book book2 = (Book) list.get(j+1); if(book1.getPrice() > book2.getPrice()){ list.set(j,book2); list.set(j+1,book1); } } } } }运行结果:
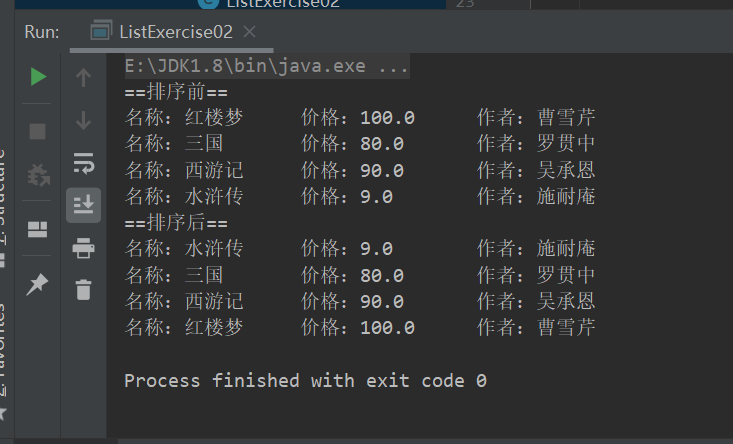
ArrayList底层源码及注意事项
-
注意事项
-
ArrayList可以加入任意元素,包括null(或者是多个null)。
package com.conllection_.lists; import java.util.ArrayList; import java.util.List; public class ArrayListDetail { public static void main(String[] args) { ArrayList arrayList = new ArrayList(); arrayList.add(null); arrayList.add("jack"); arrayList.add(null); System.out.println("list = " + arrayList); } }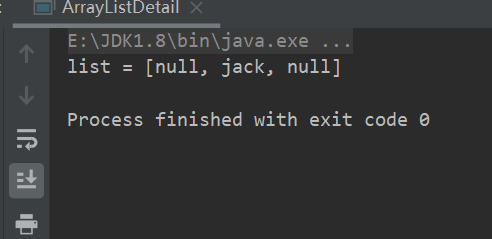
-
ArrayList是由数组来实现数据存储的
-
ArrayList基本等同于Vector,除了ArrayList是线程不安全(执行效率高)。在多线程情况下,不建议使用ArrayList。
ArrayList.add() 源码:
//ArrayList.add()的源码没有修饰词synchronized public boolean add(E e) { //Increments modCount!! ensureCapacityInternal(size + 1); elementData[size++] = e; return true; }由于该集合的方法没有用synchronized修饰,我们可以知道ArrayList是线程不安全的!下面可以跟Vector的源码进行比较
Vector.add() 源码:
public synchronized boolean add(E e) { modCount++; ensureCapacityHelper(elementCount + 1); elementData[elementCount++] = e; return true; }
-
-
ArrayList的底层源码分析(先说结论,再分析源码)
-
ArrayList中维护了一个Object类型的数组elementData。
//transient 表示瞬间,短暂的,表示该属性不会被序列化 transient Object[] elementData; -
当创建ArrayList对象时,如果使用的是无参构造器,则初始elementData容量为0,第1次添加,则扩容elementData为10,如果需要再次扩容,则扩容elementData为1.5倍(即初始化数组elementData的大小为0,初次添加数据时扩容成10,等到添加的数据达到容量极限时,继续扩容为elementData的1.5倍)。
-
如果使用的是指定大小的构造器,则初始elementData容量为指定大小,如果需要扩容则直接扩容elementData为1.5倍
-
扩容机制源码分析
-
创建ArrayListSource类。
package com.conllection_.lists; import java.util.ArrayList; public class ArrayListSource { public static void main(String[] args) { //利用无参构造创建了ArrayList ArrayList arrayList = new ArrayList(); //利用有参构造创建了ArrayList //ArrayList list = new ArrayList(8); for (int i = 0; i < 10; i++) { arrayList.add(i); } for (int i = 11; i < 15 ; i++) { arrayList.add(i); } arrayList.add(100); arrayList.add(200); arrayList.add(null); } } -
在ArrayList arrayList = new ArrayList();出添加断点,debug。
public ArrayList() { this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA; }DEFAULTCAPACITY_EMPTY_ELEMENTDATA为空数组,其定义:
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};可以知道此时创建了一个空的elementData数组={}!
-
下一步 执行arrayList.add()。add源码如下
public boolean add(E e) { ensureCapacityInternal(size + 1); // Increments modCount!! elementData[size++] = e; return true; }- 先确定是否需要扩容(ensureCapacityInternal)
- 然后再执行,赋值
-
进入ensureCapacityInternal方法。
private void ensureCapacityInternal(int minCapacity) { ensureExplicitCapacity( calculateCapacity(elementData, minCapacity)); }该方法调用了ensureExplicitCapacity与calculateCapacity方法。
calculateCapacity方法源码:
private static int calculateCapacity(Object[] elementData, int minCapacity) { if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) { //DEFAULT_CAPACITY为常量,定义为10 //minCapacity为集合所需的最小容量 return Math.max(DEFAULT_CAPACITY, minCapacity); } return minCapacity; }ensureExplicitCapacity方法源码:
private void ensureExplicitCapacity(int minCapacity) { // modCount为当前集合被修改的次数 //用来防止多个线程操作产生的异常。 modCount++; // overflow-conscious code if (minCapacity - elementData.length > 0) grow(minCapacity); }ensureCapacityInternal方法在这一步中首先调用了calculateCapacity方法来确定minCapacity(最小容量)然后把最小容量返回到ensureExplicitCapacity方法中,判断elementData的大小是够足够,如果不够会使用grow()方法去扩容。
-
然后通过调用grow方法 完成扩容。grow源码:
private void grow(int minCapacity) { // overflow-conscious code int oldCapacity = elementData.length; //按原来大小的1.5倍扩容 int newCapacity = oldCapacity + (oldCapacity >> 1); //初始值扩容 if (newCapacity - minCapacity < 0) newCapacity = minCapacity; //判断容量是否超过数组最大容量 if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); // minCapacity is usually close to size, so this is a win: // Arrays.copyOf可以把原先数组copy到新的elementData! elementData = Arrays.copyOf(elementData, newCapacity); }在这一步完成了:
- 实现扩容
- 使用扩容机制来确定要扩容到多大
- 第一次newCapacity = 10
- 第二次及其以后,按照1.5倍扩容
- 扩容使用的是Arrays.copyOf()实现,可以把原来elementData的数据copy到扩容后的elementData中
- 完成后把扩容后的数组逐层返回到add方法里面
扩容后的elementData:
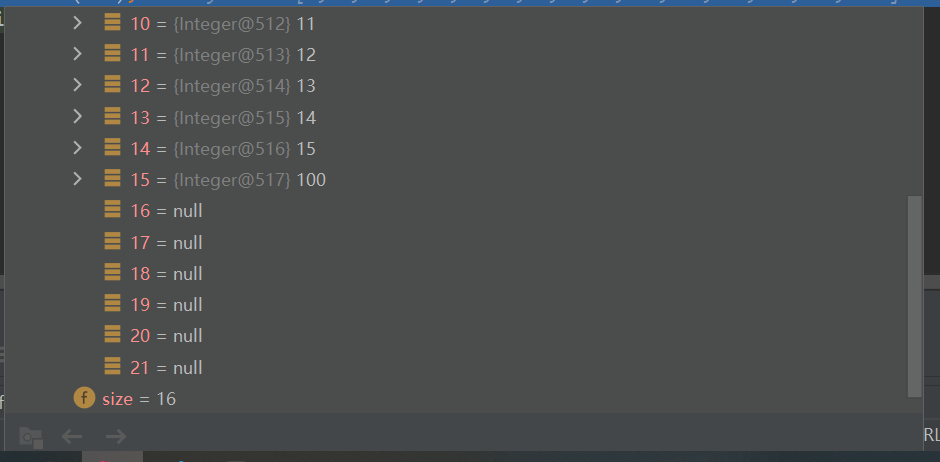
-
-
当使用有参构造器创建与使用ArrayList时,扩容机制与上述基本一致。
public ArrayList(int initialCapacity) { if (initialCapacity > 0) { this.elementData = new Object[initialCapacity]; } else if (initialCapacity == 0) { this.elementData = EMPTY_ELEMENTDATA; } else { throw new IllegalArgumentException("Illegal Capacity: "+ initialCapacity); } }this.elementData = new Object[initialCapacity]创建了指定大小的elementData数组。
initialCapacity为构造器传入的初始参数,即为elementData数组的初始大小。
需要注意的是,有参构造器扩容时第一次扩容为elementData的1.5倍,并不是初始为10!
因为calculateCapacity方法中只有elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA时才会把常量DEFAULT_CAPACITY的值返回到ensureExplicitCapacity。而DEFAULTCAPACITY_EMPTY_ELEMENTDATA为空数组。由于有参构造创建的elementData必不为空,所以初次扩容时的newCapaCity为elementData大小的1.5倍。
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) { return Math.max(DEFAULT_CAPACITY, minCapacity); }扩容后的elementData:
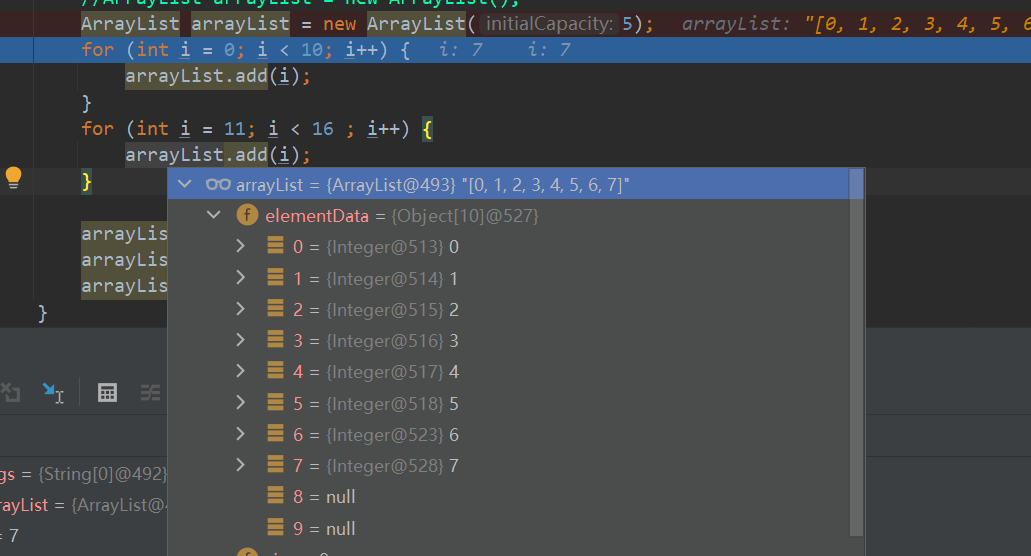
剩下的扩容步骤与无参的一样!
-
Vector底层结构和源码解析
-
Vector的定义:
public class Vector<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable -
ector底层也是一个数组,protected Object[] elementData;
-
Vector是线程同步的,即线程安全,Vector类的操作方法都带有synchronize
public synchronized boolean add(E e) { modCount++; ensureCapacityHelper(elementCount + 1); elementData[elementCount++] = e; return true; } -
Vector与ArrayList比较
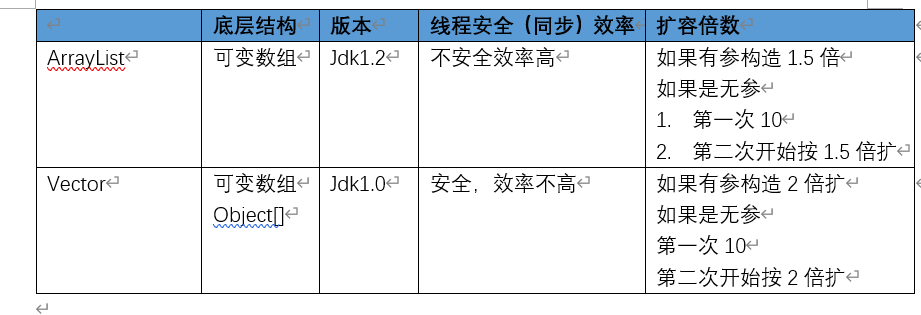
-
Vector扩容的底层源码
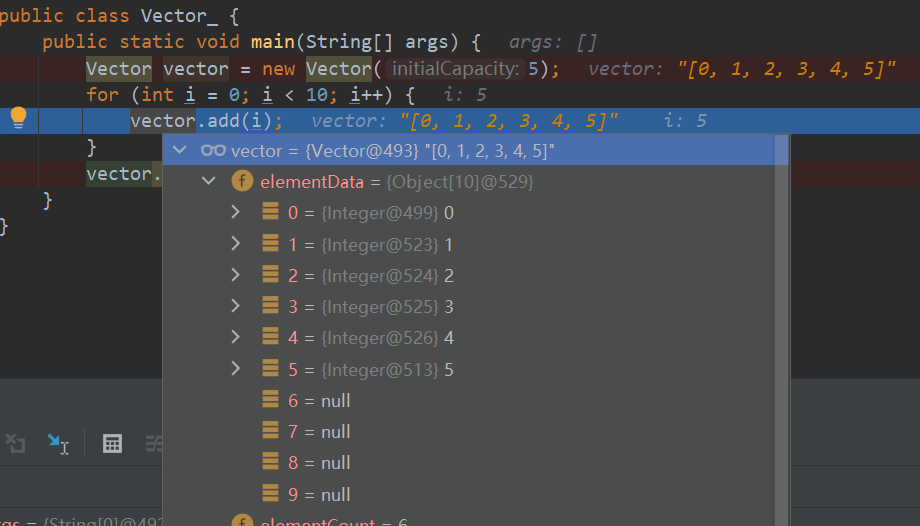
创建Vector_类,使用无参构造器来创建Vector。
package com.conllection_.lists; import java.util.Vector; public class Vector_ { public static void main(String[] args) { Vector vector = new Vector(); for (int i = 0; i < 10; i++) { vector.add(i); } vector.add(100); } }Vecto的无参创建初始化elementData大小为10
public Vector() { this(10); }进入到add方法,通过ensureCapacityHelper判断是否需要扩容。
public synchronized boolean add(E e) { modCount++; ensureCapacityHelper(elementCount + 1); elementData[elementCount++] = e; return true; }ensureCapacityHelper方法:
private void ensureCapacityHelper(int minCapacity) { // overflow-conscious code //如果最小容量大于数组的实际长度,则扩容 if (minCapacity - elementData.length > 0) grow(minCapacity); }如果minCapacity - elementData.length > 0满足,则通过grow方法扩容
private void grow(int minCapacity) { // overflow-conscious code int oldCapacity = elementData.length; int newCapacity = oldCapacity + ((capacityIncrement > 0) ? capacityIncrement : oldCapacity); if (newCapacity - minCapacity < 0) newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); elementData = Arrays.copyOf(elementData, newCapacity); }又因为capacityIncrement=0,所以newCapacity=oldCapacity+oldCapacity,即为原来的两倍!
扩容后的Vector:
LinkedList底层结构和源码解析
- LinkedList底层实现了双向链表和双端队列特点
- 可以添加任意元素(元素可以重复),包括null
- LinkedList也是线程不安全的,没有实现同步
-
LinkedList的底层操作机制
-
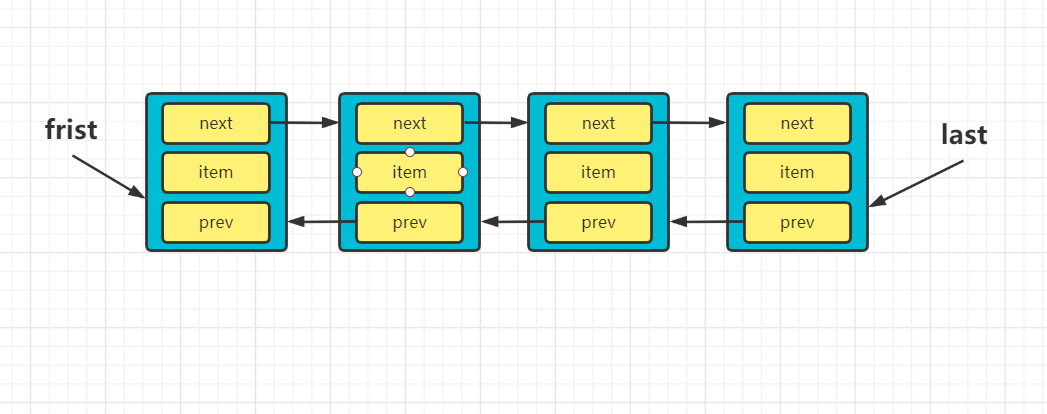
LinkedList底层维护了一个双向链表。
-
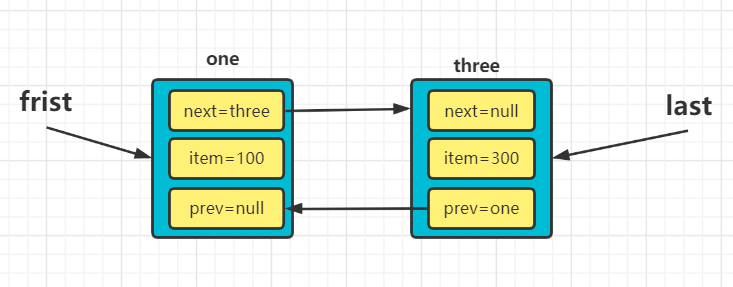
LinkedList中维护了两个属性first和last分别指向首节点和尾结点。
-
每个节点(Node对象),里面又包含prev、next、item三个属性,其中通过prev指向前一个节点,通过next指向后一个节点。最终实现双向链表。
-
所以LinkedList的元素添加和删除,不是通过数组完成的,相对来说效率较高。
-
LinkedList链表示意图:
-
-
双向链表的创建使用演示
创建Note类
package com.conllection_.lists; //定义一个Note类,Note对象表示双向链表的一个节点。 public class Note { public Object item;//存放数据 public Note pre;//指向上一个节点 public Note next;//指向下一个节点 public Note(Object name){ this.item=name; } @Override public String toString() { return "Note{" + "name=" + item + '}'; } }在LinkedList类中模拟建立一个双向链表
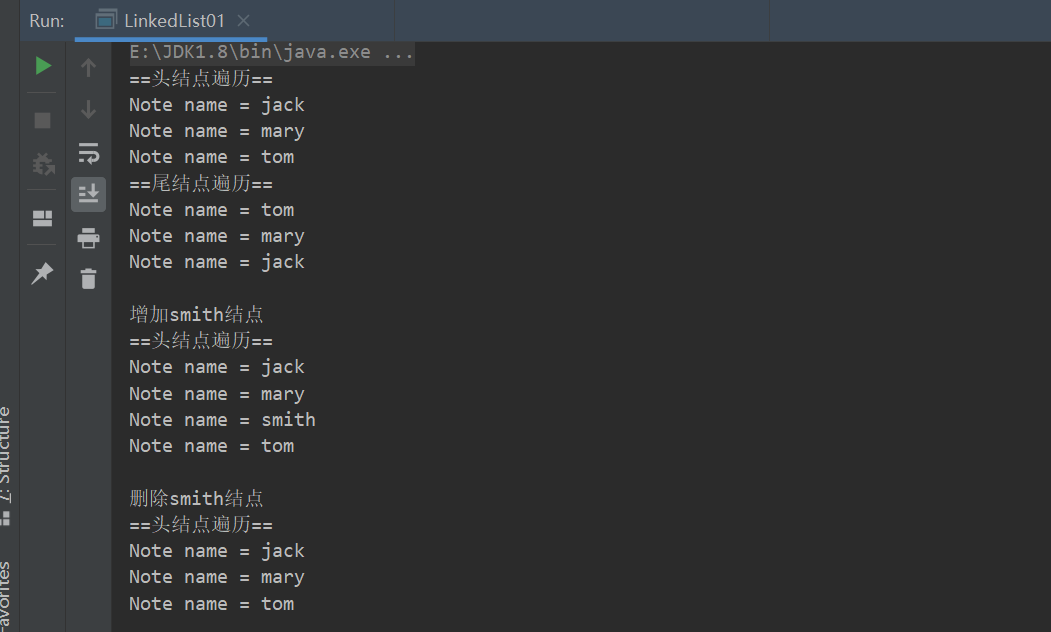
package com.conllection_.lists; public class LinkedList01 { public static void main(String[] args) { //模拟一个简单的双向链表 //首先创建三个结点 jack、mary、tom Note jack = new Note("jack"); Note mary = new Note("mary"); Note tom = new Note("tom"); //连接三个结点形成双向链表 //jack->mary->tom jack.next = mary; mary.next = tom; //tom->mary->jack tom.pre = mary; mary.pre = jack; //创建头结点与尾结点 //让first引用指向jack,就是双向链表的头结点 Note first = jack; //让last引用指向tom,就是双向链表的尾结点 Note last = tom; } }利用头结点遍历,遍历链表
//头结点遍历 System.out.println("==头结点遍历=="); while(true){ if(first == null){ break; } System.out.println(first); first = first.next; }利用尾结点遍历,遍历链表
System.out.println("==尾结点遍历=="); while(true){ if(last == null){ break; } System.out.println(last); last = last.pre; }在mary结点与tom结点之间增加一个smith结点
//在mary与tom之间增加一个smith结点 Note smith = new Note("smith"); smith.pre = mary; smith.next = tom; mary.next = smith; tom.pre = smith; first = jack; //头结点遍历 System.out.println("==头结点遍历=="); while(true){ if(first == null){ break; } System.out.println(first); first = first.next; }删除smith结点
//删除smith结点 System.out.println(); System.out.println("删除smith结点"); mary.next = tom; tom.pre = mary; first = jack; //头结点遍历 System.out.println("==头结点遍历=="); while(true){ if(first == null){ break; } System.out.println(first); first = first.next; }运行结果:
-
利用LinkedList的CRUD来查看其底层源码
LinkedListCRUD.java
package com.conllection_.lists; import java.util.LinkedList; public class LinkedListCRUD { public static void main(String[] args) { LinkedList linkedList = new LinkedList(); linkedList.add(100); linkedList.add(200); } }在LinkedList linkedList = new LinkedList();处添加断点,debug。
可以知道此时LinkedList只初始化了一个空的linkedList
public LinkedList() {}此时linkedList的属性 first = null,last = null
然后查看add方法的源码,我们可以发现add方法调用了方法linkLast
public boolean add(E e) { linkLast(e); return true; }查看linkLast方法的源码,我们可以发现此时创建了一个newNode结点,并将其加入到双向链表的最后。
void linkLast(E e) { //初始last为null,所以l=null final Node<E> l = last; final Node<E> newNode = new Node<>(l, e, null); last = newNode; if (l == null) first = newNode; else l.next = newNode; size++; modCount++; }因为是第一个结点,所以newNode的next与last均为空。此时LinkedList的first与last均指向了newNode。此时链表的状态为:
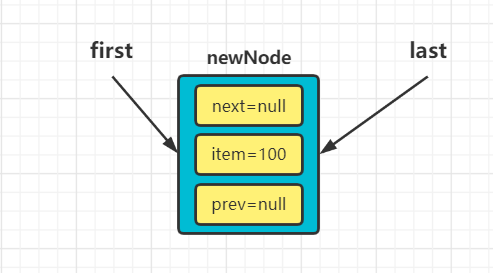
当我们再次往LinkedList集合中添加元素时,会再次进入到底层的linkLast方法。
void linkLast(E e) { //l = last 即指向了第一个newNode final Node<E> l = last; //此时新的newNode有prev = l 即新的newNode指向了第一个结点! final Node<E> newNode = new Node<>(l, e, null); last = newNode; //因为l = last 所以l不为null if (l == null) first = newNode; else l.next = newNode; size++; //modCount记录集合修改的次数 modCount++; }因为此时的last不再为空,所以结点l指向了last结点,即第一个newNode。此时链表的状态为:
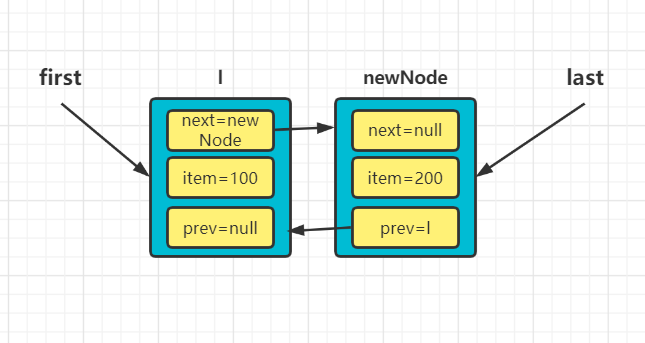
-
上述代码为LinkedList集合添加元素时的源码展示,下面我们看一下LinkedList集合删除指定索引的元素时的源码:
LinkedListCURD类
package com.conllection_.lists; import java.util.LinkedList; public class LinkedListCRUD { public static void main(String[] args) { LinkedList linkedList = new LinkedList(); linkedList.add(100); linkedList.add(200); linkedList.add(300); System.out.println("linkedList = " + linkedList); linkedList.remove(1); System.out.println("linkedList = " + linkedList); } }查看linkedList.remove(int index)方法。
public E remove(int index) { checkElementIndex(index); return unlink(node(index)); }我们可以知道该方法首先通过checkElementIndex(index);检查索引是否合法,不合法会抛出异常。
checkElementIndex(index);方法源码:
private void checkElementIndex(int index) { if (!isElementIndex(index)) throw new IndexOutOfBoundsException(outOfBoundsMsg(index)); }上述isElementIndex方法的作用用来判断元素的索引范围
private boolean isElementIndex(int index) { return index >= 0 && index < size; }当索引在元素的合法范围时,进入到了node(int index)方法。该方法可以返回指定元素索引处的(非空)结点。
Node<E> node(int index) { // assert isElementIndex(index); //如果index小于size的一半,从头到尾遍历 if (index < (size >> 1)) { Node<E> x = first; for (int i = 0; i < index; i++) x = x.next; return x; } else { //如果index大于size的一半,从尾到头遍历 Node<E> x = last; for (int i = size - 1; i > index; i--) x = x.prev; return x; } }然后再通过unlink(Node x)方法删除指定索引集合元素。
E unlink(Node<E> x) { // assert x != null; //把要删除的元素数据赋值给element,以便删除后返回 final E element = x.item; //新建一个结点next指向x.next final Node<E> next = x.next; //新建一个结点prev指向x.prev final Node<E> prev = x.prev; //如果prev == null 说明x结点为头结点。 //此时把first指向next,即说明x的下一个结点为新的头结点 if (prev == null) { first = next; } else {//否则x的上一个节点的next值指向x的下一个结点 prev.next = next; //因为x已经删除,所以把prev置为null x.prev = null; } //如果next == null 说明该节点为尾结点 //此时吧last指向prev,即说明x的上一个结点为新的尾结点 if (next == null) { last = prev; } else {//否则把x的下一个结点的prev指向x的上一个结点 next.prev = prev; //因为x已经删除,next x.next = null; } x.item = null; //集合的大小减一 size--; //修改次数+1次 modCount++; //最后返回被删除的元素 return element; }下面为删除two结点的图解
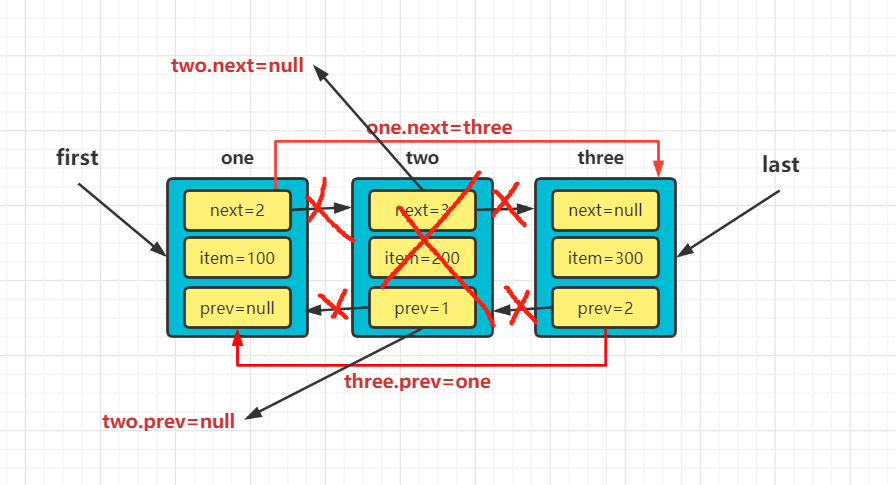
删除后的链表状态为
-
ArrayList和LinkedList比较

-
如何选择ArrayList和LinkedList
- 如果我们改查的操作多,就选ArrayList
- 如果我们增删操作多,就选择LinkedList
- 一般来说,在程序中,80%—90%都是查询,因此大部分情况下会选择ArrayList
- 在一个项目中,根据业务灵活选择,也可能这样,一个模块使用的是ArrayList,另一个模块使用的是LinkedList