Java集合类(二)
- Set接口和常用方法
- HashSet全面说明
- 思考
- HashSet底层解析
- HashSet底层添加元素源码分析
- HashSet扩容机制和转换红黑树机制源码解析
- threshold补充说明
- LinkedHashSet说明及源码分析
- LinkedHashSet全面说明
- LinkedHashSet底层机制示意图
- LinkedHashSet底层源码分析
Set接口和常用方法
-
Set接口基本介绍
- 无序(添加和取出的顺序不一致),没有索引
- 不允许重复元素,所以最多包含一个null
- JDK API中Set接口常用的实现类有:HashSet、TreeSet等
-
Set接口的常用方法
- 和List接口一样,Set接口也是Collection的子接口,因此,常用方法和Collection接口一样。(详情见Java集合类(一))
-
以Set接口的实现类HashSet来讲解Set接口的方法
package com.conllection_.sets; import java.util.HashSet; import java.util.Set; public class SetMethod { public static void main(String[] args) { Set set = new HashSet(); set.add("john"); set.add("jack"); set.add("tom"); set.add("john"); set.add(null); set.add(null); System.out.println("set = " + set); } }运行结果:
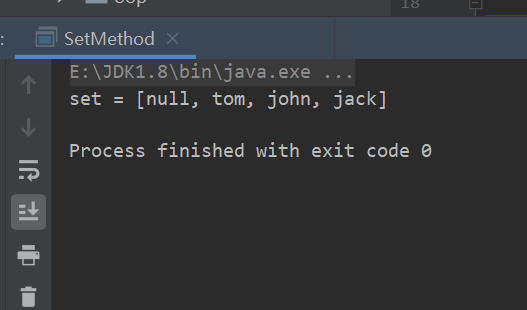
结论:
- set接口的实现类的对象(set接口对象),不能存放重复的元素,可以添加null
- set接口对象存放数据是无序(即添加的顺序和取出的顺序不一致)
- 取出的顺序虽然不是添加的属性,但是顺序是固定的!
-
Set接口的遍历方式
同Collection的便利方式一样,因为Set接口是Collection接口的子接口。
-
使用迭代器
System.out.println("===迭代器遍历==="); Iterator iterator = set.iterator(); while (iterator.hasNext()) { Object next = iterator.next(); System.out.println("set = "+next); } -
增强for
System.out.println("增强for遍历"); for (Object o: set) { System.out.println("set = "+o); } -
不能使用索引的方式来获取
-
HashSet全面说明
-
HashSet实现了Set接口
-
HashSet实际上是HashMap
public HashSet() { map = new HashMap<>(); } -
可以存放null值,但是只能有一个
-
HashSet不保证元素是有序的,取决于hash后,再确定索引的结果(即不保证存放元素的顺序与取出顺序一致)
-
不能有重复元素或对象
package com.conllection_.sets; import java.util.HashSet; import java.util.Set; public class HashSet01 { public static void main(String[] args) { Set hashSet = new HashSet(); /*说明 * 1. 在执行add方法后,会返回一个Boolean值 * 2. 如果添加成功,返回true,否则返回false * 3. 可以通过remove指定删除哪个对象 * */ System.out.println(hashSet.add("mary"));//T System.out.println(hashSet.add("mary"));//F hashSet.add("jack");//可以添加 hashSet.add("jack");//添加失败 //由于下面每一次add都新建了一个Dog对象 //所以下面两个Dog对象都会添加成功 hashSet.add(new Dog("tom")); hashSet.add(new Dog("tom")); System.out.println("HashSet = "+ hashSet); hashSet.remove("mary");//删除mary System.out.println("HashSet = "+ hashSet); } }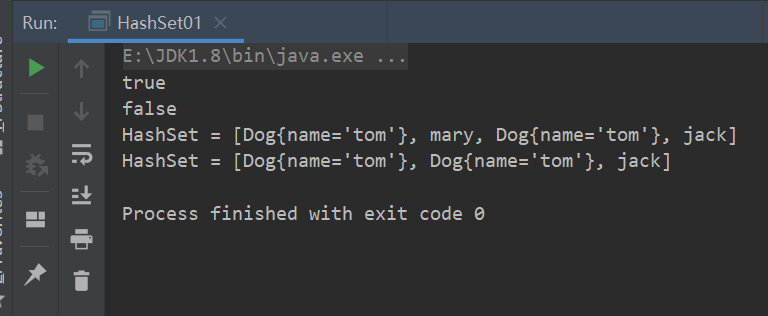
思考
-
下面两个String对象都会被添加到HashSet集合里面去吗?
hashSet.add(new String("czh")); hashSet.add(new String("czh"));运行的结果是仅有一个数据被添加,为什么呢?
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))因为此时String类型重写的equals()方法是比较其字符串内容是否相同,所以此时添加的两个“czh”数据只有一个能被添加进去。
而上述Dog对象的添加原理也是类似。
下面我们通过解读HashSet的底层结构解决这个问题!
HashSet底层解析
-
因为HashSet的底层是HashMap,所以分析HashMap底层是(数组+链表+红黑树)即可
为了更好理解HashMap的底层,下面模拟一个简单的数组+链表结构
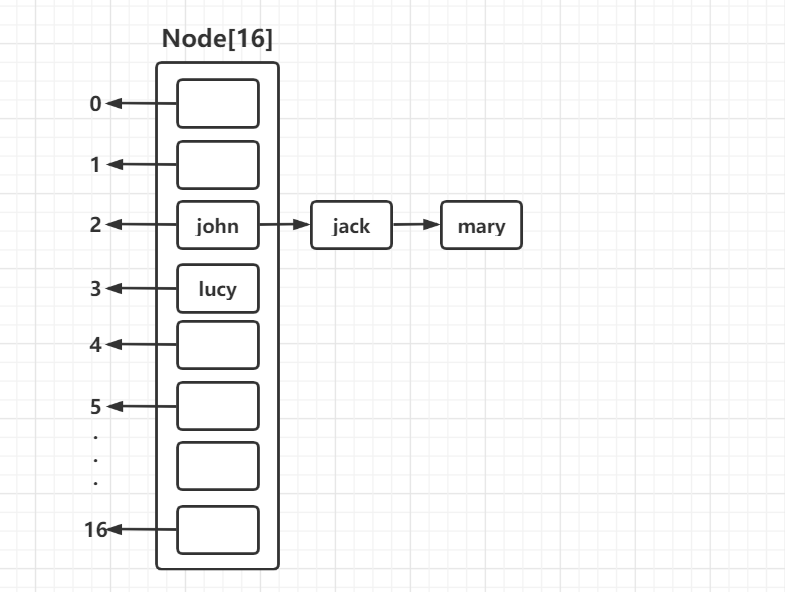
创建Node结点
//结点Node,item存储数据,next指向下一个结点,可以形成链表 class Node{ Object item; Node next; public Node(Object item, Node next) { this.item = item; this.next = next; } }创建HashSetStructure类
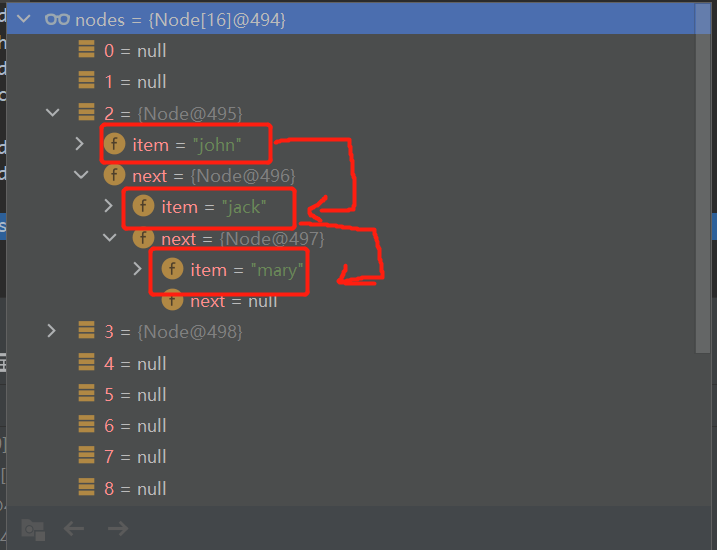
package com.conllection_.sets; public class HashSetStructure { public static void main(String[] args) { //1. 创建一个类型为Node的数组 Node[] nodes = new Node[16]; //2. 创建结点 Node john = new Node("john", null); nodes[2] = john; Node jack = new Node("jack", null); john.next = jack; Node mary = new Node("mary", null); jack.next = mary; Node lucy = new Node("lucy", null); nodes[3] = lucy; System.out.println("node = "+nodes); } }运行结果:
HashSet底层添加元素源码分析
-
分析HashSet添加元素的底层是如何实现的(hash()+equals())
- HashSet底层就是HashMap
- 添加一个元素时,先通过hash()得到hash值,然后转换成索引值
- 找到存储数据表table,看这个索引位置是否已经存放了元素
- 如果没有,直接添加
- 如果有元素,调用equals比较,如果元素内容相同,就放弃添加,如果不相同,则添加到最后
- 在Java8中,如果一条链表的元素个数到达TREEIFY_THRESHOLD(默认是8),并且table的大小>=MIN_TREEIFY_CAPACITY(默认64),就会进行树化(红黑树)。
- 当元素个数到达TREEIFY_THRESHOLD但table的大小小于MIN_TREEIFY_CAPACITY(默认64)时,系统会把table表填扩容到64,然后进行树化。
-
HashSet添加元素的源码解读
创建HashSetSource类,用于debug
package com.conllection_.sets; import java.util.HashSet; import java.util.Set; public class HashSetSource { public static void main(String[] args) { HashSet hashSet = new HashSet(); hashSet.add("jack"); hashSet.add("tom"); hashSet.add("jack"); System.out.println("set = " + hashSet); } }-
执行构造器
public HashSet() { map = new HashMap<>(); }可以清晰地知道HashSet的底层就是HashMap
-
执行add()方法
public boolean add(E e) {//e="jack" return map.put(e, PRESENT)==null; }PRESENT是hashSet为了能使用hashMap而定义的一个常量(定值),无论添加了多少的元素它都不会变化
private static final Object PRESENT = new Object(); -
执行put()方法
public V put(K key, V value) {//key = "jack" return putVal(hash(key), key, value, false, true); }value为PRESENT,是共享的。
-
执行hash方法,计算key的hash值
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }如果key != null,程序会执行Object类中的hashCode()方法来获取key的值,并将它进行无符号右移16位(为了防止key的hashCode值发生冲突),最后得到的h为key对应的hash值。
hash值并不是hashCode,因为(h = key.hashCode()) ^ (h »> 16)
-
获取到hash值后,执行putVal方法(重要!)
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i;//定义了辅助变量 if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); else { Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; if (++size > threshold) resize(); afterNodeInsertion(evict); return null; }在此方法中,因为辅助变量tab的初始值为null,所以进入到resize()方法,给tab表赋予初始大小。
if ((tab = table) == null || (n = tab.length) == 0){ n = (tab = resize()).length; }上述代码中的table为hashMap的一个属性,类型为Node[]
因为初始的table为null,所以执行resize()方法
//下面代码为resize()方法的一些初始赋值 Node<K,V>[] oldTab = table;//结点oleTab表示原先的表 //oldCap表示初始表的容量大小 int oldCap = (oldTab == null) ? 0 : oldTab.length; //oldThr为当前表的一个临界值,当达到临界值时会扩容 int oldThr = threshold; int newCap, newThr = 0;因为初始的table为null,所以oldCap为0,所以进入到下述语句
else { // zero initial threshold signifies using defaults newCap = DEFAULT_INITIAL_CAPACITY; newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); }DEFAULT_INITIAL_CAPACITY为hashMap定义的常量,大小为16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16所以newCap= 16,即第一次扩容大小为16
newThr为表的一个临界值,是使用负载因子DEFAULT_LOAD_FACTOR乘以初始大小等到的一个值。
默认负载因子(0.75)在时间和空间成本上提供了很好的折衷。较高的值会降低空间开销,但提高查找成本(体现在大多数的HashMap类的操作,包括get和put)。设置初始大小时,应该考虑预计的entry数在map及其负载系数,并且尽量减少rehash操作的次数。如果初始容量大于最大条目数除以负载因子,rehash操作将不会发生。
使用newThr是为了减少冲突,增加一个缓冲区,避免在多线程向表中增加数据时,表的内存不够而导致死锁。
初始化tap的大小之后,会判断**(p = tab[i = (n - 1) & hash])**是否为null,(n - 1) & hash是位运算,详解见HashMap数学原理。计算出来的i为该key值在table表中的索引位置。
if ((p = tab[i = (n - 1) & hash]) == null){ tab[i] = newNode(hash, key, value, null); }如果p=null,表示还没有存放元素,执行**tab[i] = newNode(hash, key, value, null);**创建一个Node(key=“jack",value=PRESENT)把hash也放进Node是为了下次添加元素时比较。
执行完毕,此时我们可以发现此时table表中已经在刚刚计算出来的索引值上添加了“jack”。
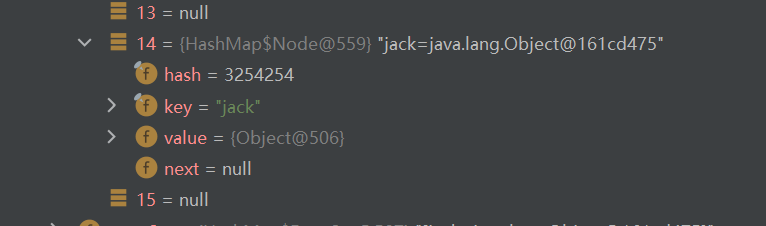
到此为止,HashMap的第一次添加元素分析完毕。
当我们向HashMap集合表再次添加数据时,系统会计算其hash值,然后通过
if ((p = tab[i = (n - 1) & hash]) == null){ tab[i] = newNode(hash, key, value, null); }方法判断该hash值对应的索引位置上是否已经存在值,如果不存在,即把新增的key添加到表中的该索引位置上。
此时可以发现,table表上多了一个数据
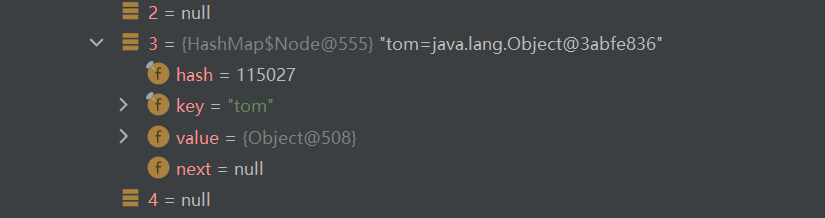
如果该hash值对应的索引位置上已经存在值,程序会跳到下面语句
//p为当前索引位置上对应的链表的第一个元素,即已经添加的值 //所以p.hash为已存在值得hash值,p.key为已存在值得key值 if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))){ e = p; }如果当前索引位置上对应的链表的第一个元素的hash值与需要添加的key的hash值一样
且满足以下两个条件之一:
- 准备添加的key值与p指向的Node结点的key是同一个对象
- p指向的Node结点的key的equals()和准备假如的key比较后相同。
需要注意的是,此时equals()方法不能理解为只比较字符串内容是否相同,因为每一个类都会有其对应的equals()方法,所以equals()方法的比较内容可以由程序员所重写的方法来决定!
此时说明新增加的key值已存在,所以该key值不会被添加到table中。
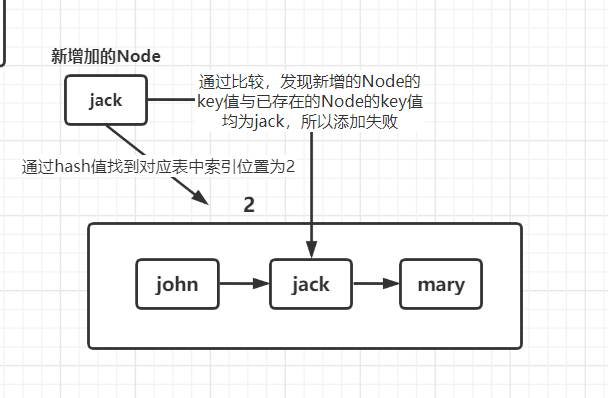
若不满足上述条件,程序会继续往下走,执行下面语句。
else if (p instanceof TreeNode){ e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); }上述语句会判断p是否为红黑树,如果是红黑树,就调用putTreeVal进行添加。
如果p不是红黑树,执行以下代码
else { for (int binCount = 0; ; ++binCount) { //这是条件1 if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } //这是条件2 if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } }因为在可以执行上述代码时,说明此时table表中是使用链表的方式来存储数据 。
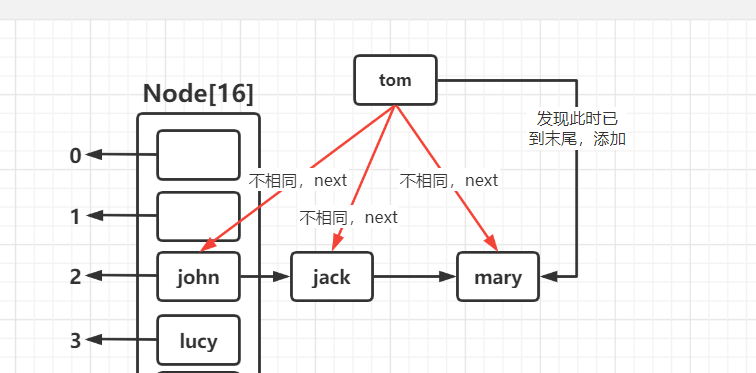
此时进入一个死循环,退出的条件:
-
条件1:在要加入的位置i = (n - 1) & hash处所形成的链表没有一个结点与要加入的结点相同时,退出循环,此时就加在最末尾。添加成功
-
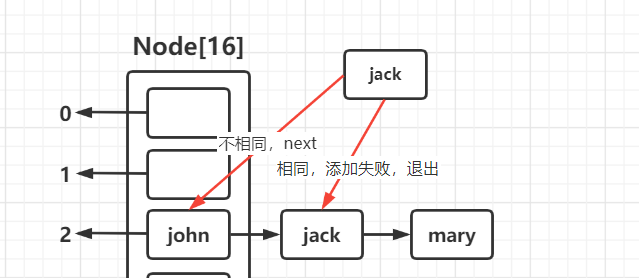
条件2 :在要加入的位置i = (n - 1) & hash处所形成的链表有结点与要加入的结点相同,此时退出循环,添加失败
两个条件结合起来使用
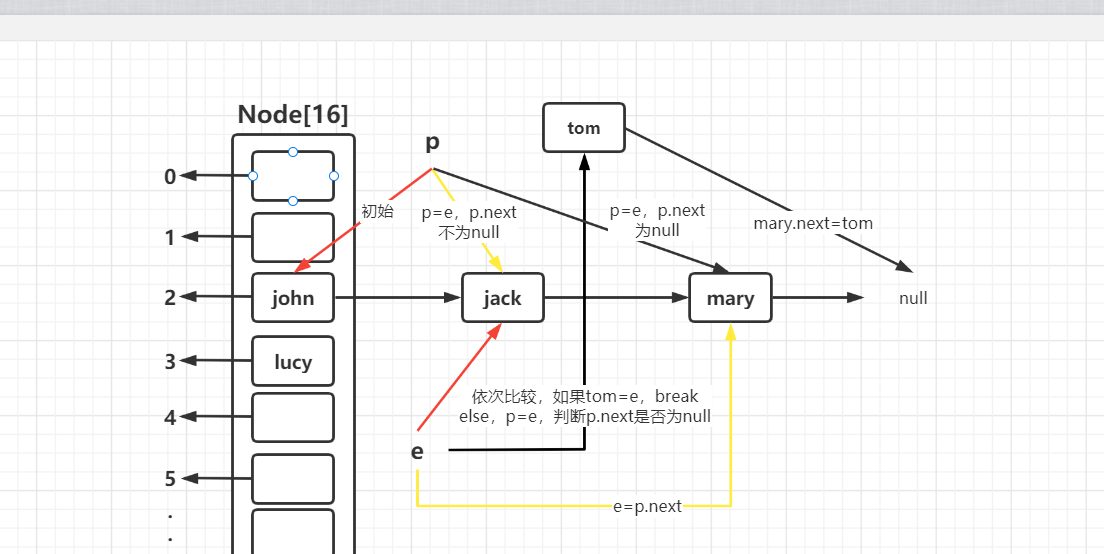
需要注意的是当我们把元素添加到聊表后,会进行以下判断
if (binCount >= TREEIFY_THRESHOLD - 1){ // -1 for 1st treeifyBin(tab, hash); }判断链表是否已经达到8个结点(TREEIFY_THRESHOLD=8)。如果到达,则调用treeifyBin(tab, hash)方法对当前链表进行树化(转换成红黑树)。
注意,在转换成红黑树时,treeifyBin(tab, hash)方法会进行判断
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY){ resize(); }判断table表大小是否<64,如果小于64,会先将table表进行扩容,再进行树化。
-
HashSet扩容机制和转换红黑树机制源码解析
-
HashSet底层是HashMap,第一次添加时,table数组扩容到16,临界值(threshold)=16*负载因子(loadFactor)0.75 = 12
-
如果数组使用到了临界值12,就会扩容到16*2=32,新的临界值就是 32 * 0.75 = 24,依次类推
-
在Java8中,如果一条链表的元素个数到达TREEIFY_THRESHOLD(默认是8),并且table的大小>=MIN_TREEIFY_CAPACITY(默认是64),就会进行树化(转换红黑树),否则任然采用数组扩容机制
创建测试类HashSetIncrement.java
package com.conllection_.sets; import java.util.HashSet; import java.util.Objects; public class HashSetIncrement { public static void main(String[] args) { HashSet hashSet = new HashSet(); for (int i = 1; i <=12; i++) { hashSet.add(new A(i)); } System.out.println("hashSet = "+ hashSet); } }Class A
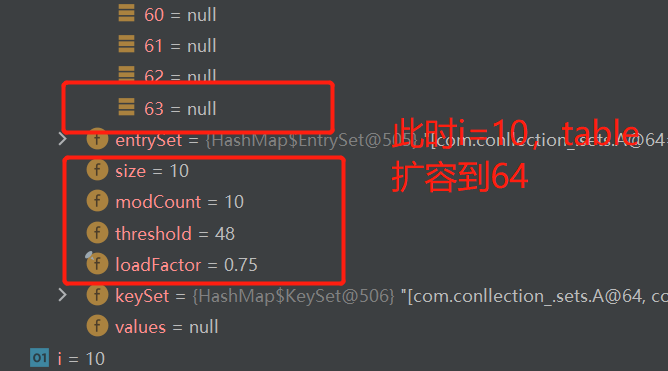
class A { private int n ; public A(int n) { this.n = n; } @Override public int hashCode() { return 100; } }在HashSetIncrement类中的for循环处加一个断点,debug。可以发现,当i=9时,即满足一条链表的元素个数到达TREEIFY_THRESHOLD(默认是8),此时触发转换红黑树机制。
但是此时不满足table表大小>=64
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY){ resize(); }所以此时table表会进行扩容。
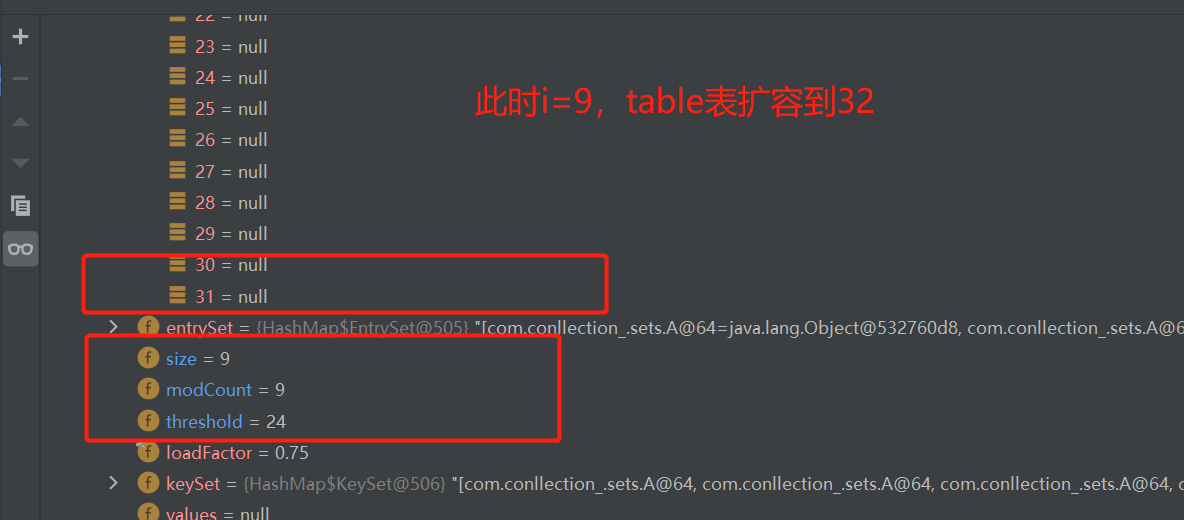
继续执行,可以发现table再次扩容。
再继续执行,可以发现此时链表已经发生树化(转换成红黑树)
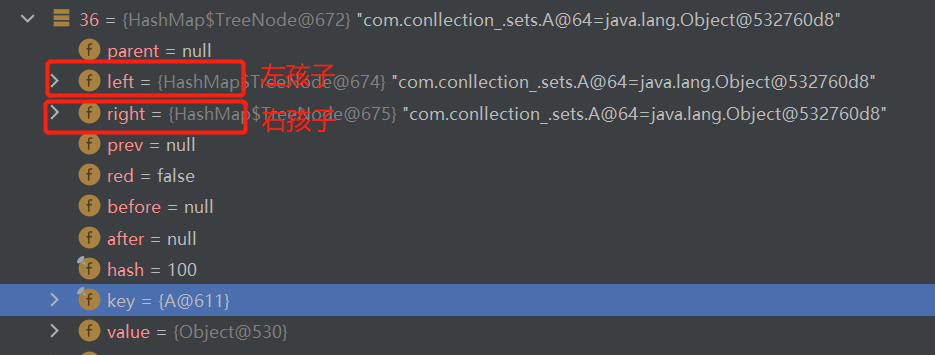
树化过程的源码
else if ((e = tab[index = (n - 1) & hash]) != null) { TreeNode<K,V> hd = null, tl = null; do { TreeNode<K,V> p = replacementTreeNode(e, null); if (tl == null) hd = p; else { p.prev = tl; tl.next = p; } tl = p; } while ((e = e.next) != null); if ((tab[index] = hd) != null) hd.treeify(tab); }
threshold补充说明
-
在putVal方法中,有这么一行代码
++modCount; if (++size > threshold){ resize(); } afterNodeInsertion(evict);modCount代表我们对table表修改的次数。
其中size是每当我们加入一个结点Node(key,value,hash,next),size++。
所以当我们想table表中加入指定数量的Node结点是,也会触发扩容机制。
代码演示HashSetIncrement类
package com.conllection_.sets; import java.util.HashSet; import java.util.Objects; public class HashSetIncrement { public static void main(String[] args) { HashSet hashSet = new HashSet(); for (int i = 1; i <=7; i++) { hashSet.add(new A(i)); } for (int i = 1; i <=7; i++) { hashSet.add(new B(i)); } System.out.println("hashSet = "+ hashSet); } }Class A 与 Class B
class B { private int n ; public B(int n) { this.n = n; } @Override public int hashCode() { return 200; } } class A { private int n ; public A(int n) { this.n = n; } @Override public int hashCode() { return 100; } }运行调试,可以发现,虽然我们在一条链表上增加了7个元素,然后第二条链表增加到第五个元素时size=12,也触发了扩容机制
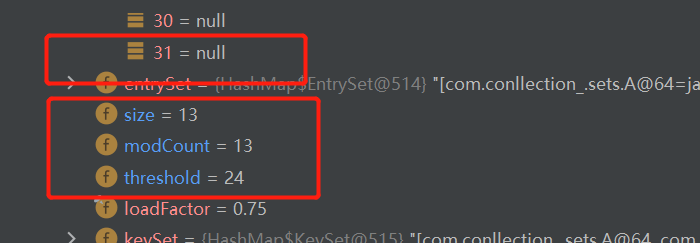
所以触发扩容机制的前提是累积添加元素到达threshold。
LinkedHashSet说明及源码分析
LinkedHashSet全面说明
- LinkedHashSet是HashSet的子类。
- LinkedHashSet底层是一个LinkedHashMap,底层维护了一个数组+双向链表。
- LinkedHashSet根据元素的HashCode值来决定元素的存储位置,同时使用链表维护元素的次序,这使得元素看起来是一插入顺序保存的。
- LinkedHashSet不允许添加重复元素。
LinkedHashSet底层机制示意图
-
示意图
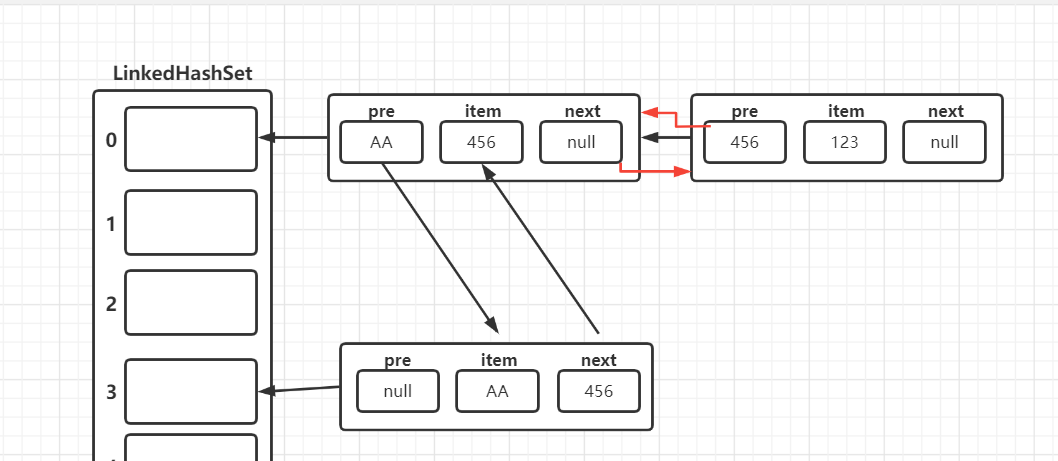
-
双向链表具体机制与LinkedList底层结构类似。
LinkedHashSet底层源码分析
说明
-
在LInkedHashSet中维护了一个hash表和双向链表(LinkedHashSet有head和tail)
-
每个节点有before和after属性,这样可以形成双向链表
-
在添加一个元素时,先求hash值,再求索引。确定该元素在hashtable的位置,然后将添加的元素加入到双向链表(如果已经存在,不添加;原则跟hashset一样)
-
所以,我们遍历LinkedHash可以确定插入顺序和取出顺序一致
创建LinkedHashSetSource类,用于分析源码
package com.conllection_.sets; import java.util.LinkedHashSet; import java.util.Set; public class LinkedHashSetSource { public static void main(String[] args) { Set set = new LinkedHashSet(); set.add(new String("AA")); set.add(456); set.add(456); set.add(123); set.add("czh"); System.out.println("LinkedHashSet = " + set); } }可以知道,添加第一次时,系统会将数组table扩容到16,存放的结点类型是LinkedHashMap$Entry
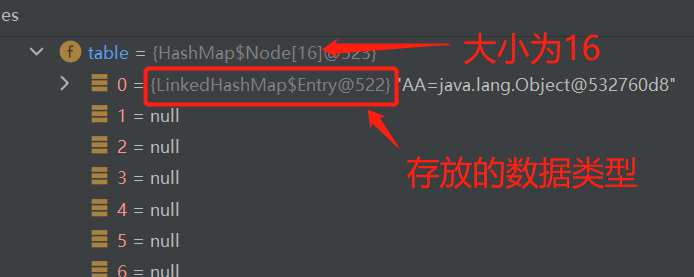
为什么数组时HashMap$Node[]类型,而存放的元素/数据却是LinkedHashMap$Entry呢?
下面我们查看LinkedHashMap底层源码来解决这个问题。
static class Entry<K,V> extends HashMap.Node<K,V> { Entry<K,V> before, after; Entry(int hash, K key, V value, Node<K,V> next) { super(hash, key, value, next); } }我们可以发现上面这个在LinkedHashMap源码中的静态内部类Entry继承了HashMap.Node。即数组的多态。双向链表实现的关键也是在这里。
继续往下调试
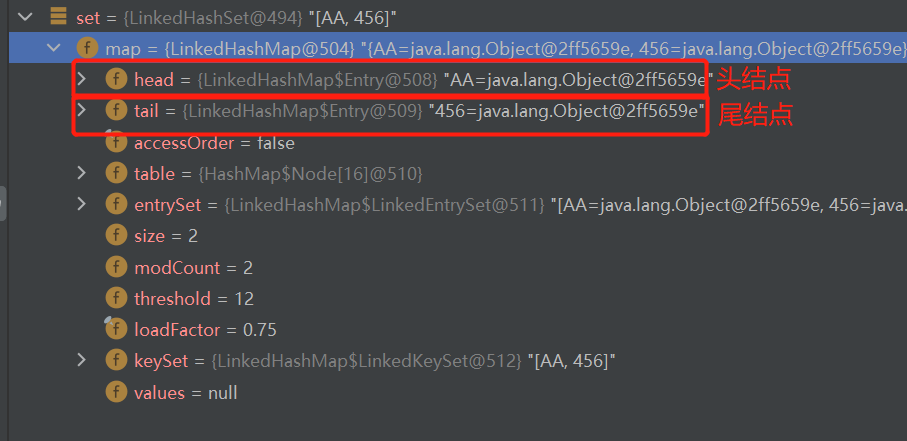
此时的map与hashSet的不一样,多了几个属性。其中head表示双向链表中的头结点,tail表示尾结点。
而每一个结点又有before与after属性,指向上一个结点与下一个结点。
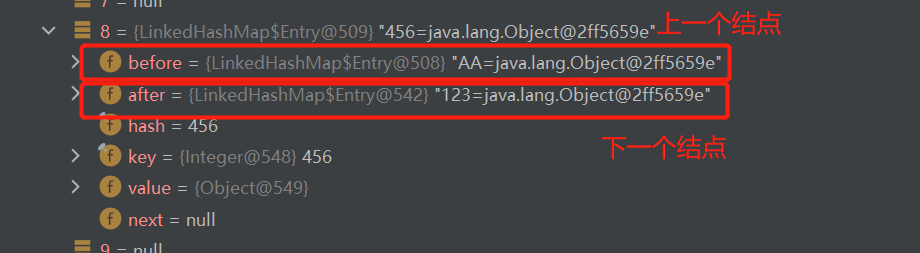
所以LinkedHashSet可以实现按顺序插入及取出。
进入add()方法
public boolean add(E e) { return map.put(e, PRESENT)==null; }可以知道LinkedHashSet添加元素底层就是HashSet添加元素的底层(因为LinkedHashSet是HashSet的实现子类)