Java集合类(四)
- 开发中如何选择集合实现类
- TreeSet底层源码剖析
- TreeMap底层源码剖析
- Collections工具类
- 集合章节练习题
开发中如何选择集合实现类
- 在开发中,选择什么集合实现类,主要取决于业务操作特点,然后根据集合实现类特性进行选择,分析如下:
- 先判断存储的类型(一组对象[单列]或一组键值对[双列])
- 一组对象[单列]:Collection接口
- 允许重复:List
- 增删多:LinkedLike(底层维护了一个双向链表)
- 改查多:ArrayList(底层维护了Object类型的可变数组)
- 不允许重复:Set
- 无序:HashSet(底层是HashMap,维护了一个哈希表【数组+链表+红黑树】)
- 排序:TreeSet
- 插入和取出顺序一致:LinkeHashSet(底层是LinkedHashMap),维护了数组+双向链表
- 允许重复:List
- 一对键值对:Map
- 键无序:HashMap(底层是哈希表,jdk7:数组+链表,jdk8:数组+链表+红黑树)
- 键排序:TreeMap
- 键插入和取出顺序一致:LinkedHashMap(底层是HashMap)
- 读取文件:Properties
TreeSet底层源码剖析
-
TreeSet的底层就是TreeMap
- key不允许重复。
-
TreeSet可以实现有序排序,但是当我们使用其无参构造器时,仍然是无序的。要使用TreeSet提供的一个构造器,传入一个比较器(匿名内部类)才能实现排序
下面使用TreeSet对数据进行排序(按字符串长度比较)
创建测试类TreeSet_
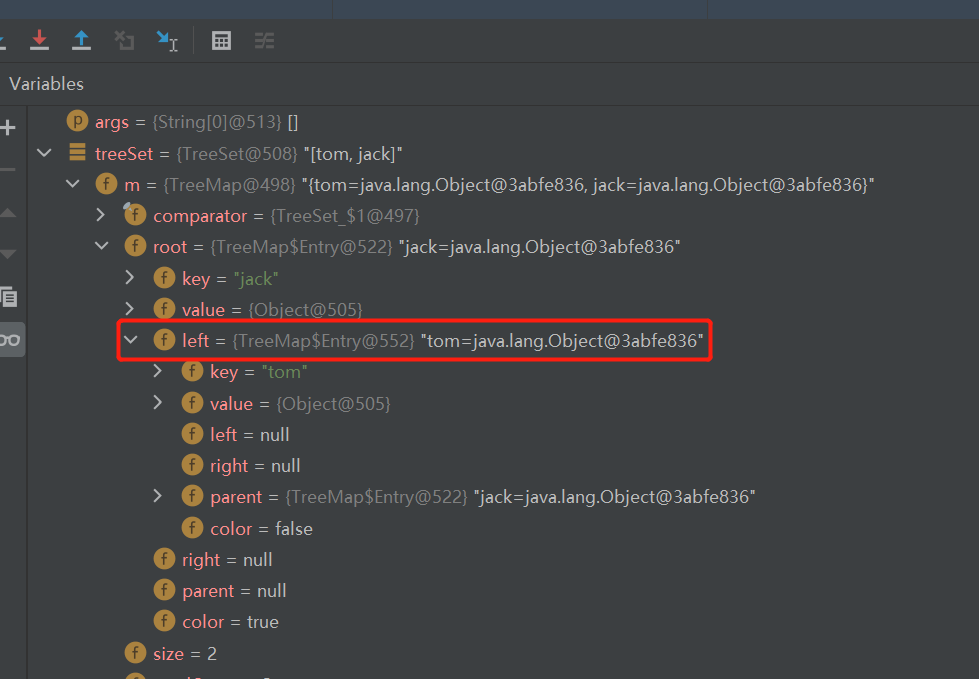
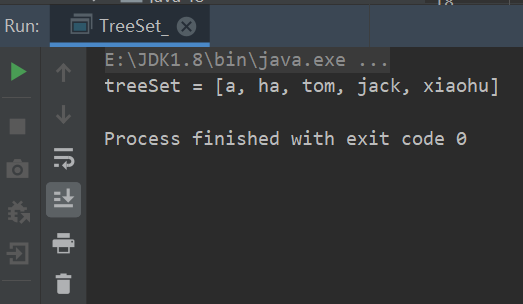
package com.conllection_.sets; import java.util.Comparator; import java.util.TreeSet; public class TreeSet_ { public static void main(String[] args) { TreeSet treeSet = new TreeSet(new Comparator() { @Override public int compare(Object o1, Object o2) { //按字符串长度进行比较 return ((String)o1).length() - ((String)o2).length(); } }); treeSet.add("jack"); treeSet.add("tom"); treeSet.add("a"); treeSet.add("ha"); treeSet.add("xiaohu"); System.out.println("treeSet = " +treeSet); } }debug调试,我们可以看到TreeSet此时使用的构造器
public TreeSet(Comparator<? super E> comparator) { this(new TreeMap<>(comparator)); }可以发现,该构造器把我们的一个比较器(匿名内部类)对象传到了TreeSet的底层TreeMap
public TreeMap(Comparator<? super K> comparator) { this.comparator = comparator; }并且把比较器对象赋给了TreeMap的属性comparator。
在调用treeSet.add(“tom”);时,在底层会执行put的方法
public boolean add(E e) { return m.put(e, PRESENT)==null; }继续往下走,可以发现程序执行以下代码
int cmp; Entry<K,V> parent; // split comparator and comparable paths //cpr为我们传进去的匿名内部类 Comparator<? super K> cpr = comparator; if (cpr != null) { do { parent = t; //动态绑定到我们的匿名内部类对象,且调用了其compare方法。 cmp = cpr.compare(key, t.key); if (cmp < 0) t = t.left; else if (cmp > 0) t = t.right; else//如果两个元素比较后相等,即返回0,这个key就不能加入进去 return t.setValue(value); } while (t != null); }此时的treeSet集合如下
运行结果
需要注意的是,排序规则可以自己定义,按照需求来定义。
TreeMap底层源码剖析
-
TreeMap机制与TreeSet大体一致,但TreeMap是键值对方式存储数据
-
TreeMap底层实现的是Entry数组
创建TreeMap_测试类
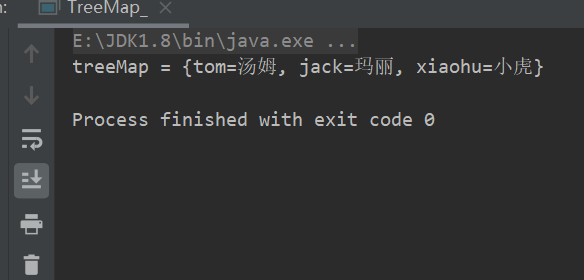
package com.conllection_.maps; import java.util.Comparator; import java.util.TreeMap; public class TreeMap_ { public static void main(String[] args) { //使用有参构造,重写比较器 TreeMap treeMap = new TreeMap(new Comparator() { @Override public int compare(Object o1, Object o2) { //按照字符串长度进行比较 return ((String)o1).length()-((String)o2).length(); } }); treeMap.put("jack","杰克"); treeMap.put("tom","汤姆"); treeMap.put("xiaohu","小虎"); treeMap.put("mary","玛丽");//替换杰克 System.out.println("treeMap = "+ treeMap); } }调试程序,执行put方法,首次添加时会进行初始化
Entry<K,V> t = root; if (t == null) { compare(key, key); // type (and possibly null) check root = new Entry<>(key, value, null); size = 1; modCount++; return null; }因为此时只有一个元素,不能进行比较,所以就直接添加到Entry里面了
继续添加元素,程序执行以下代码
int cmp; Entry<K,V> parent; // split comparator and comparable paths Comparator<? super K> cpr = comparator; if (cpr != null) { do { parent = t; cmp = cpr.compare(key, t.key); if (cmp < 0) t = t.left; else if (cmp > 0) t = t.right; else return t.setValue(value); } while (t != null); }此时会调动到比较器进行比较,与TreeSet不同的是当key值比较结果相同时,程序会把新增的key的value值替换掉原来的key的value值。
需要注意的是,key不能为null
Collections工具类
-
Collections是一个操作Set、List和Map等集合的工具类
-
Collections中提供了一系列静态的方法对集合元素进行排序、查询和修改等操作
-
排序操作(均为static方法)
- reverse(List):反转List中元素的顺序
- shuffle(List):对List集合元素进行随机排序
- sort(List):根据元素的自然顺序对指定List集合元素按升序排序
- sort(List,Comparator):根据指定的Comparator产生的顺序对List元素进行排序
- swap(List,int,int):将指定List集合中的i处元素和j处元素进行交换
代码演示
创建Collections01测试类
package com.collections_; import java.util.ArrayList; import java.util.Collections; import java.util.Comparator; import java.util.List; public class Collections02 { public static void main(String[] args) { List list = new ArrayList(); list.add("jack"); list.add("tom"); list.add("smith"); list.add("h"); System.out.println("list = "+list); // 1. reverse(List):反转List中元素的顺序 Collections.reverse(list); System.out.println("将list反转后"); System.out.println("list = "+list); // 2. shuffle(List):对List集合元素进行随机排序 Collections.shuffle(list); System.out.println("将list元素进行随机排序后"); System.out.println("list = "+list); // 3. sort(List):根据元素的自然顺序对指定List集合元素按升序排序 Collections.sort(list); System.out.println("自然排序后"); System.out.println("list = "+list); // 4. sort(List,Comparator):根据指定的Comparator产生的顺序对List元素进行排序 Collections.sort(list, new Comparator() { @Override public int compare(Object o1, Object o2) { //按字符串长度排序 //可以加入一些校验代码,提高严谨性 return ((String)o1).length()-((String)o2).length(); } }); System.out.println("按字符串长度排序后"); System.out.println("list = "+list); // 5. swap(List,int,int):将指定List集合中的i处元素和j处元素进行交换 Collections.swap(list,1,3); System.out.println("将下标为1的元素与下标为3的元素互换"); System.out.println("list = "+list); } }运行结果:
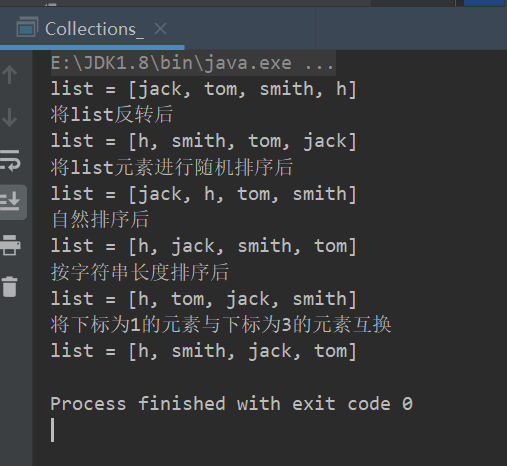
-
查找、替换
- Object max(Collection):根据元素的自然顺序,返回给定集合中的最大元素
- Object max(Collection,Comparator):根据Comparator指定的顺序。返回给定集合中的最大元素
- Object min(Collection):根据元素的自然顺序,返回给定集合中的最小元素
- Object min(Collection,Comparator):根据Comparator指定的顺序。返回给定集合中的最小元素
- int frequency(Collection,Object):返回指定集合中指定元素的出现次数
- void copy(List dest,List src):将src中的内容复制到dest中
- boolean replaceAll(List list,Object oldVal,Object newVal):使用新值替换List对象的所有旧值
代码演示
创建Collections02测试类
package com.collections_; import java.util.ArrayList; import java.util.Collections; import java.util.Comparator; import java.util.List; public class Collections02 { public static void main(String[] args) { List list = new ArrayList(); list.add("jack"); list.add("tom"); list.add("smith"); list.add("h"); System.out.println("List = "+list); // 1. Object max(Collection):根据元素的自然顺序,返回给定集合中的最大元素 System.out.println("返回自然顺序中的最大元素"); System.out.println("然顺序中的最大元素是"+Collections.max(list)); // 2. Object max(Collection,Comparator):根据Comparator指定的顺序。返回给定集合中的最大元素 System.out.println("返回Comparator指定的顺序中的最大元素"); //比如返回字符串长度最长元素 Object maxObject = Collections.max(list, new Comparator() { @Override public int compare(Object o1, Object o2) { return ((String)o1).length() - ((String) o2).length(); } }); System.out.println("字符串长度最长元素是" + maxObject); // 3. Object min(Collection):根据元素的自然顺序,返回给定集合中的最小元素 // 4. Object min(Collection,Comparator):根据Comparator指定的顺序。返回给定集合中的最小元素 // 5. int frequency(Collection,Object):返回指定集合中指定元素的出现次数 System.out.println("tom出现的次数为" + Collections.frequency(list, "tom")); // 6. void copy(List dest,List src):将src中的内容复制到dest中 ArrayList dest = new ArrayList(); for (int i = 0; i < list.size(); i++) { dest.add(""); } Collections.copy(dest,list); System.out.println("dest = "+ dest); // 7. boolean replaceAll(List list,Object oldVal,Object newVal):使用新值替换List对象的所有旧值 Collections.replaceAll(list,"tom","汤姆"); System.out.println("替换后"); System.out.println("list = " + list); } }运行结果:
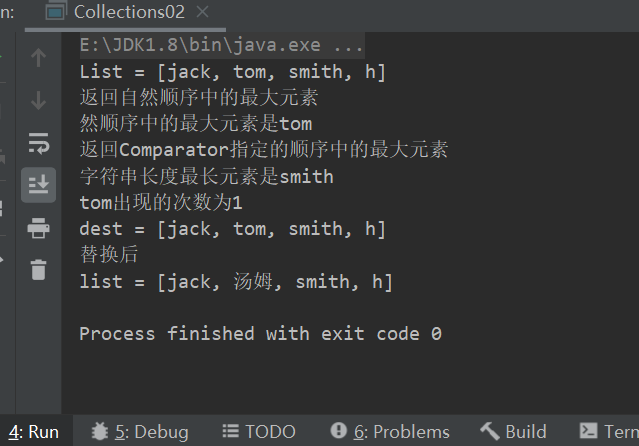
需要注意的是,使用copy时,dest数组的大小必须大于src数组,否则会报数组越界异常

int srcSize = src.size(); if (srcSize > dest.size()){ throw new IndexOutOfBoundsException("Source does not fit in dest"); }
本章练习题
-
试分析HashSet和TreeSet分别如何实现去重的
-
HashSet去重机制:HashSet是通过hashCode()+equals()方法实现去重的。底层先通过hashCode方法计算出key对应的hash值,然后通过hash值查找在table表上对应索引位置上是否已经存在值。如果该位置上不存在值,则直接把key添加进去。否则通过equals方法遍历比较新增的key与已存在的key是否相同,相同就把key加入到已存在的key的后面,否则不添加。equals方法可以自定义比较的内容。
-
TreeSet去重机制:如果你在定义TreeSet时传入了一个Comparator匿名内部类(比较器),就使用该比较器中定义的compare方法实现去重。如果返回是0,则说明添加元素相同,不添加。如果你没有传入一个Comparator匿名内部类,系统会通过你添加的对象实现的Comprareable接口的compareTo实现去重。
else { if (key == null) throw new NullPointerException(); @SuppressWarnings("unchecked") //把k指向key对象的类型实现的Comparable接口 Comparable<? super K> k = (Comparable<? super K>) key; do { parent = t; //动态绑定compareTo方法 cmp = k.compareTo(t.key); if (cmp < 0) t = t.left; else if (cmp > 0) t = t.right; else return t.setValue(value); } while (t != null); }
-
-
分析下面代码运行会不会抛出异常,并从源码层面说明原因
TreeSet treeSet = new TreeSet(); treeSet.add(new Person()); class Person{ }会抛出ClassCastException异常
因为在定义TreeSet时没有传进去一个Comparator匿名类,所以在执行add的时候,程序会进入下述代码中
else { if (key == null) throw new NullPointerException(); @SuppressWarnings("unchecked") //把k指向key对象的类型实现的Comparable接口 Comparable<? super K> k = (Comparable<? super K>) key; do { parent = t; //动态绑定compareTo方法 cmp = k.compareTo(t.key); if (cmp < 0) t = t.left; else if (cmp > 0) t = t.right; else return t.setValue(value); } while (t != null); }又因为Person类并没有实现Comparable接口,所以运行到第6行代码处时会抛出ClassCastException异常。
-
已知:Person类按照id和name重写了hashCode与equals方法。下面代码会输出什么?
Exercises04测试类
package com.collections_; import java.util.HashSet; import java.util.Objects; public class Exercises04 { public static void main(String[] args) { Person p1 = new Person(1001,"AA"); Person p2 = new Person(1002,"BB"); HashSet set = new HashSet(); set.add(p1); set.add(p2); System.out.println(set); p1.name = "CC"; set.remove(p1); System.out.println(set); set.add(new Person(1001,"CC")); System.out.println(set); set.add(new Person(1001,"AA")); System.out.println(set); } }Person类
class Person{ public int id; public String name; public Person(int id, String name) { this.id = id; this.name = name; } public int getId() { return id; } public void setId(int id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Person person = (Person) o; return id == person.id && Objects.equals(name, person.name); } @Override public int hashCode() { return Objects.hash(id, name); } @Override public String toString() { return "Person{" + "id=" + id + ", name='" + name + '\'' + '}'; } }输出结果为
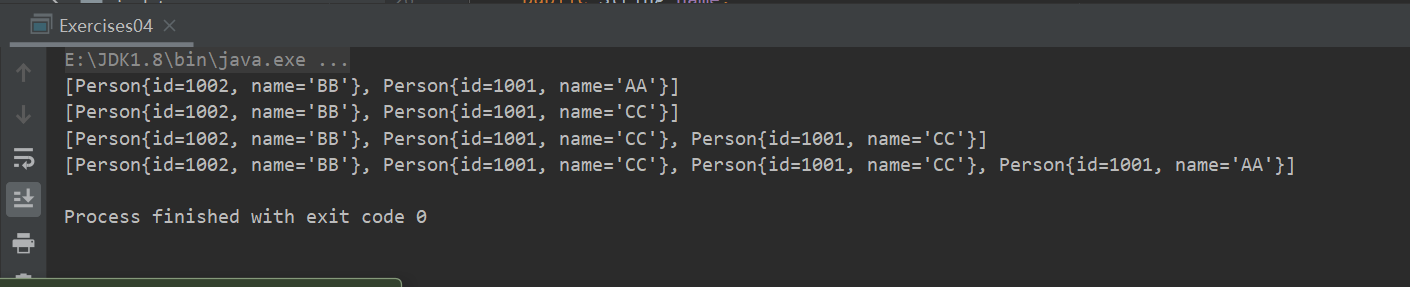
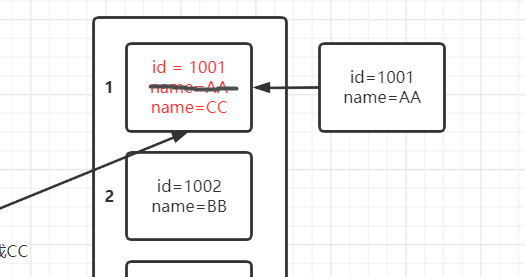
为什么set.remove(p1);执行了却没有remove成功呢?
因为在执行remove方法之前,我们把p1的name值改变了**p1.name = “CC”;**而且我们在Person类中重写了hashCode方法,所以我们把name值改变的同时导致p1对应的hash值也发生改变。而我们观看remove的源码可以知道
final Node<K,V> removeNode(int hash, Object key, Object value, boolean matchValue, boolean movable)此处传进去的hash值为p1更改后hash值
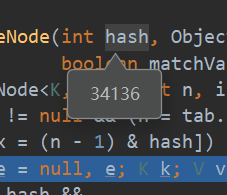
而辅助变量p却指向了table表中的p1,即hash值为table的hash值
if ((tab = table) != null && (n = tab.length) > 0 && (p = tab[index = (n - 1) & hash]) != null)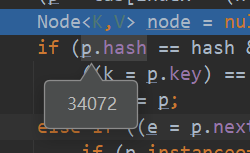
因为两个hash值不同,所以在接下来的几个if判断中结果都为false
final Node<K,V> removeNode(int hash, Object key, Object value, boolean matchValue, boolean movable) { Node<K,V>[] tab; Node<K,V> p; int n, index; if ((tab = table) != null && (n = tab.length) > 0 && (p = tab[index = (n - 1) & hash]) != null) { Node<K,V> node = null, e; K k; V v; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))//False node = p; else if ((e = p.next) != null) {//False if (p instanceof TreeNode) node = ((TreeNode<K,V>)p).getTreeNode(hash, key); else { do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) { node = e; break; } p = e; } while ((e = e.next) != null); } } //False if (node != null && (!matchValue || (v = node.value) == value || (value != null && value.equals(v)))) { if (node instanceof TreeNode) ((TreeNode<K,V>)node).removeTreeNode(this, tab, movable); else if (node == p) tab[index] = node.next; else p.next = node.next; ++modCount; --size; afterNodeRemoval(node); return node; } } return null; }所以最后只能return null;然后回到remove方法
public V remove(Object key) { Node<K,V> e; return (e = removeNode(hash(key), key, null, false, true)) == null ? null : e.value; }因为removeNode方法return null,所以返回到remove也只能return null 即修改失败。
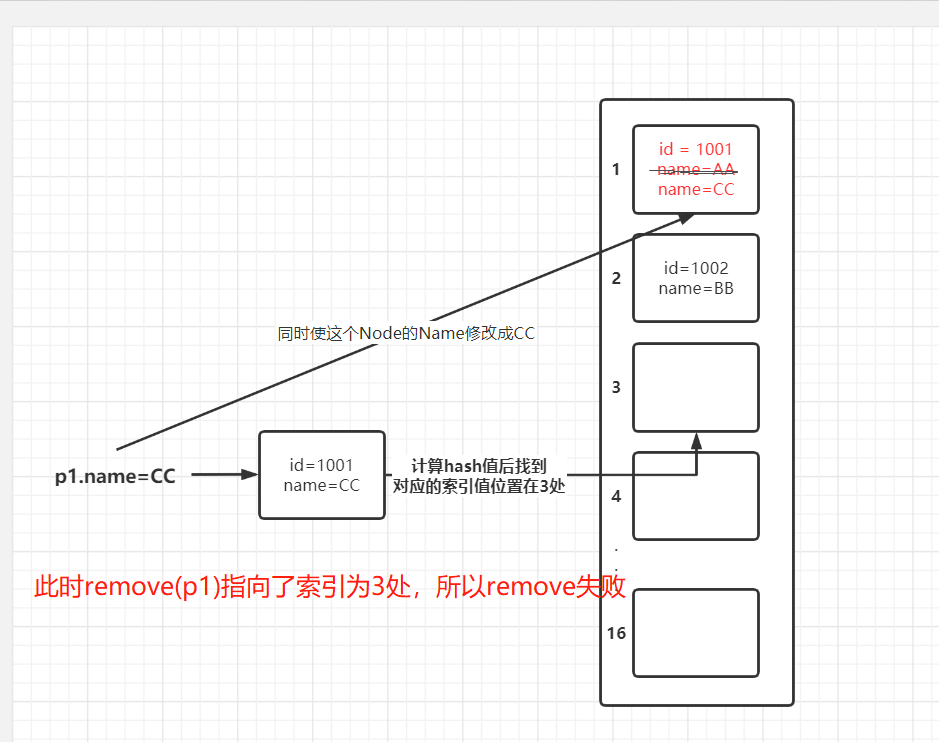
而后面添加
set.add(new Person(1001,"CC")); set.add(new Person(1001,"AA"));可以成功,原理跟上述图示一样
因为后面添加的Person(1001,“AA”)同上面一样是指向索引为3处(该处为null),所以添加成功
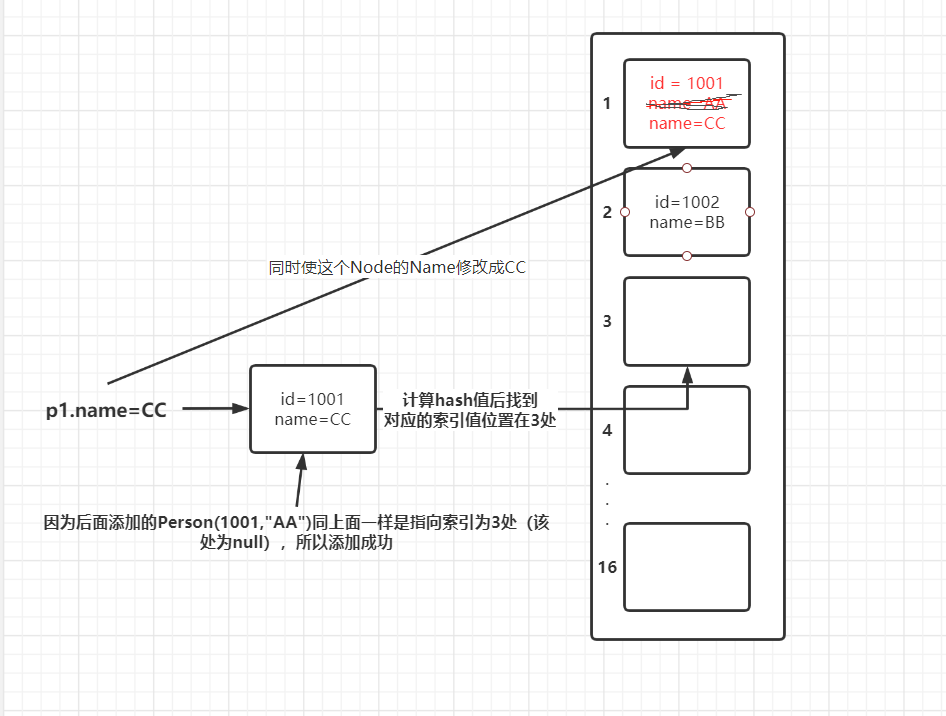
而Person(1001,“AA”)添加成功是因为此时索引为1出的Person值的name已发生改变。且计算出来的Hash值与索引为1处对应。所以该Person添加到索引为1处的Person后面